mudler/LocalAI
LocalAI is the open-source AI engine. Run any model - LLMs, vision, voice, image, video - on any hardware. No GPU required.
Backblaze Generative Media Hackathon
Build the next generation of AI media apps with Genblaze, stored on Backblaze B2. $10,000 in prizes.
Loading star history...
Use Cases & Benefits
- LocalAI is a free, open-source, self-hosted alternative to OpenAI and Claude, enabling local AI inference on consumer-grade hardware without requiring GPUs.
- It supports multiple AI model architectures including gguf, transformers, diffusers, and offers features like text, audio, video, image generation, voice cloning, and distributed P2P inference.
- Strengths include broad hardware acceleration support (NVIDIA, AMD, Intel, Apple Metal, Vulkan), lightweight modular backends, and extensive API compatibility with OpenAI standards.
- With 34,839 stars and 2,721 forks since March 2023, LocalAI shows strong community adoption and active development, including integrations with Kubernetes, Docker, and various AI tools.
- Ideal for developers and organizations seeking privacy-focused, GPU-independent local AI deployments for multimodal generation, distributed inference, and OpenAI-compatible API usage.
About LocalAI
![]()
![]()
![]()
:bulb: Get help - ❓FAQ 💭Discussions :speech_balloon: Discord :book: Documentation website
💻 Quickstart 🖼️ Models 🚀 Roadmap 🥽 Demo 🌍 Explorer 🛫 Examples Try on
![]()
![]()
![]()
![]()
LocalAI is the free, Open Source OpenAI alternative. LocalAI act as a drop-in replacement REST API that's compatible with OpenAI (Elevenlabs, Anthropic... ) API specifications for local AI inferencing. It allows you to run LLMs, generate images, audio (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families. Does not require GPU. It is created and maintained by Ettore Di Giacinto.
📚🆕 Local Stack Family
🆕 LocalAI is now part of a comprehensive suite of AI tools designed to work together:
|
|
LocalAGIA powerful Local AI agent management platform that serves as a drop-in replacement for OpenAI's Responses API, enhanced with advanced agentic capabilities. |

|
LocalRecallA REST-ful API and knowledge base management system that provides persistent memory and storage capabilities for AI agents. |
Screenshots
| Talk Interface | Generate Audio |
|---|---|
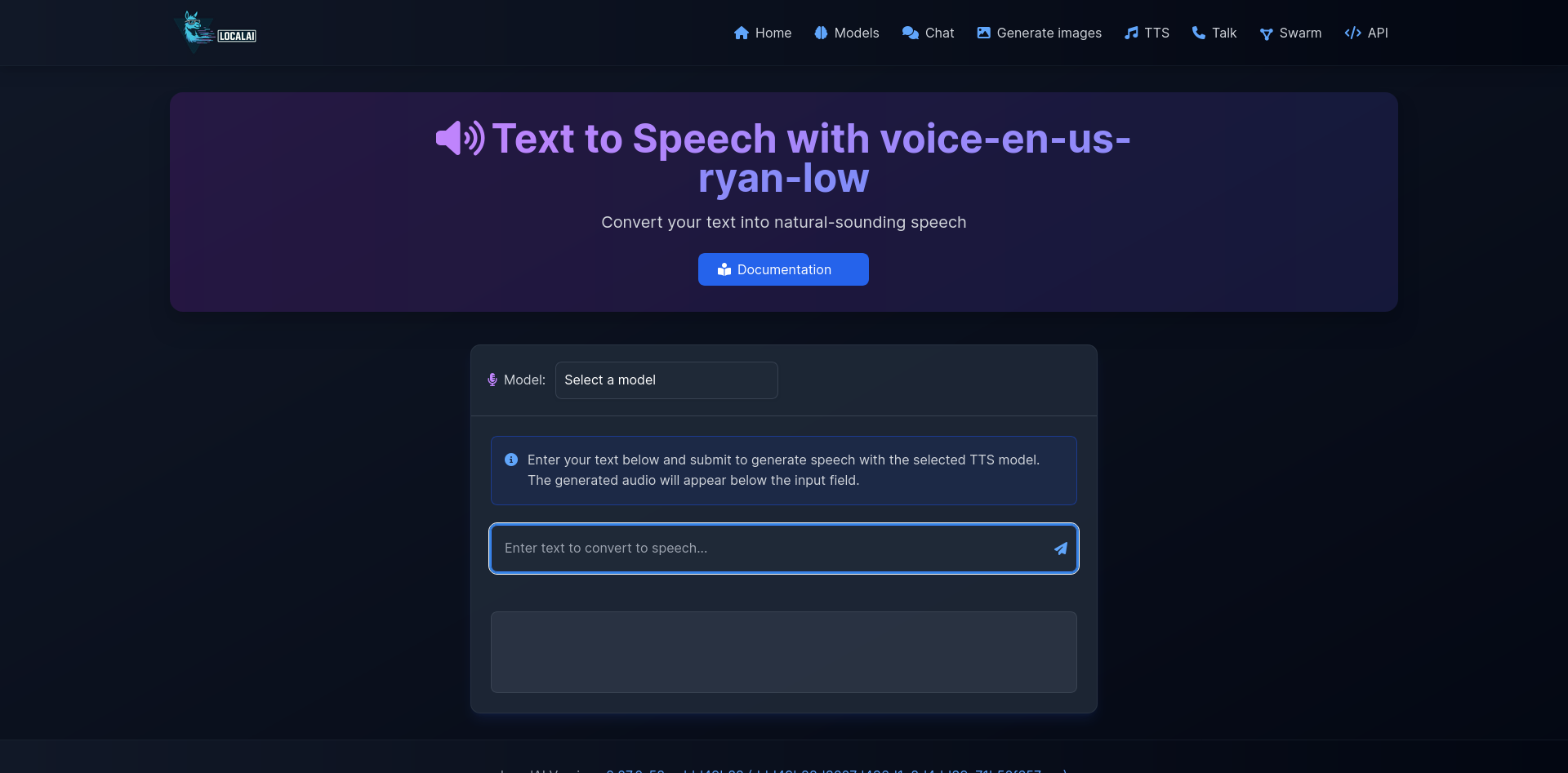 | |
| Models Overview | Generate Images |
|---|---|
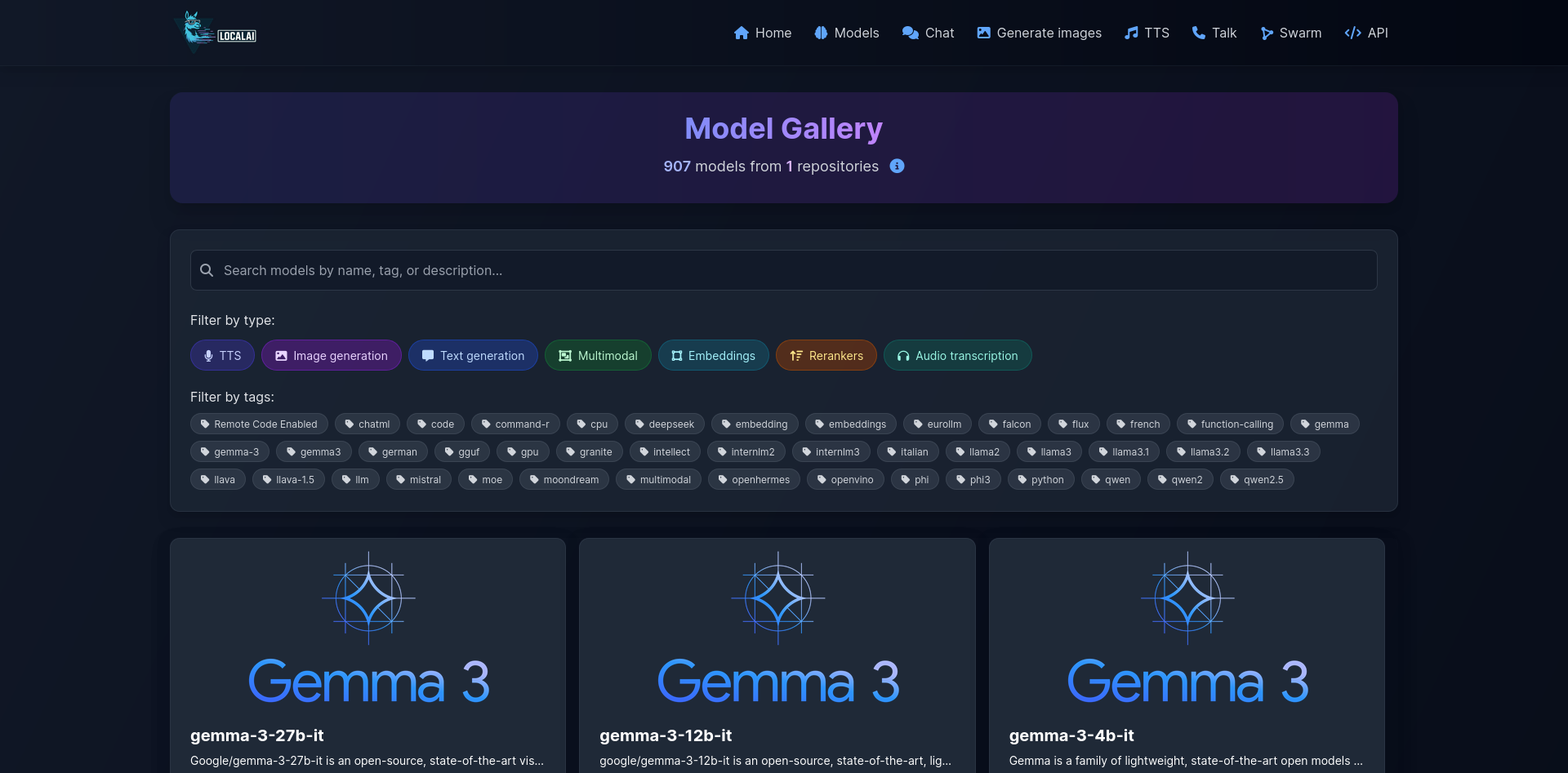 | 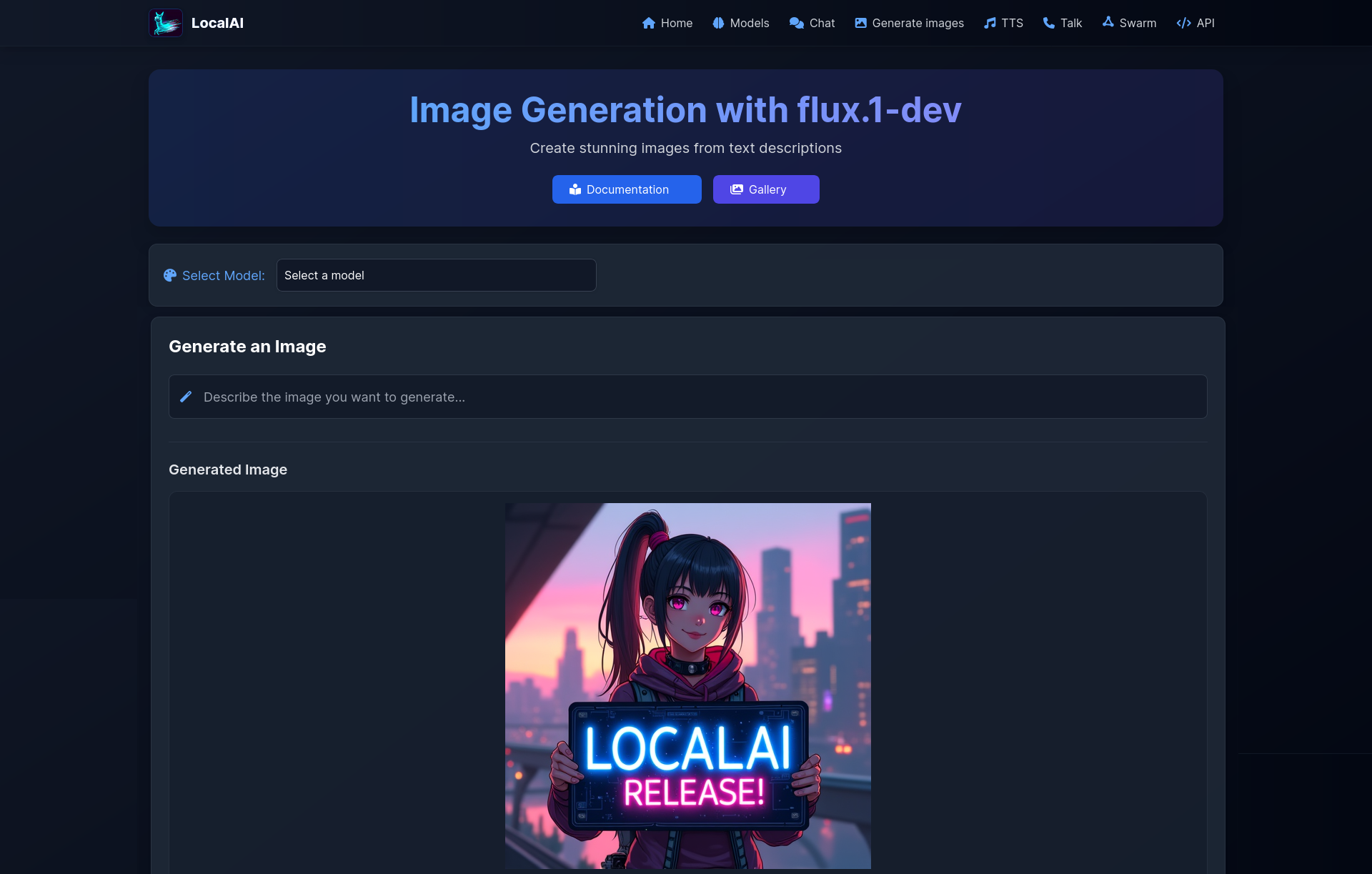 |
| Chat Interface | Home |
|---|---|
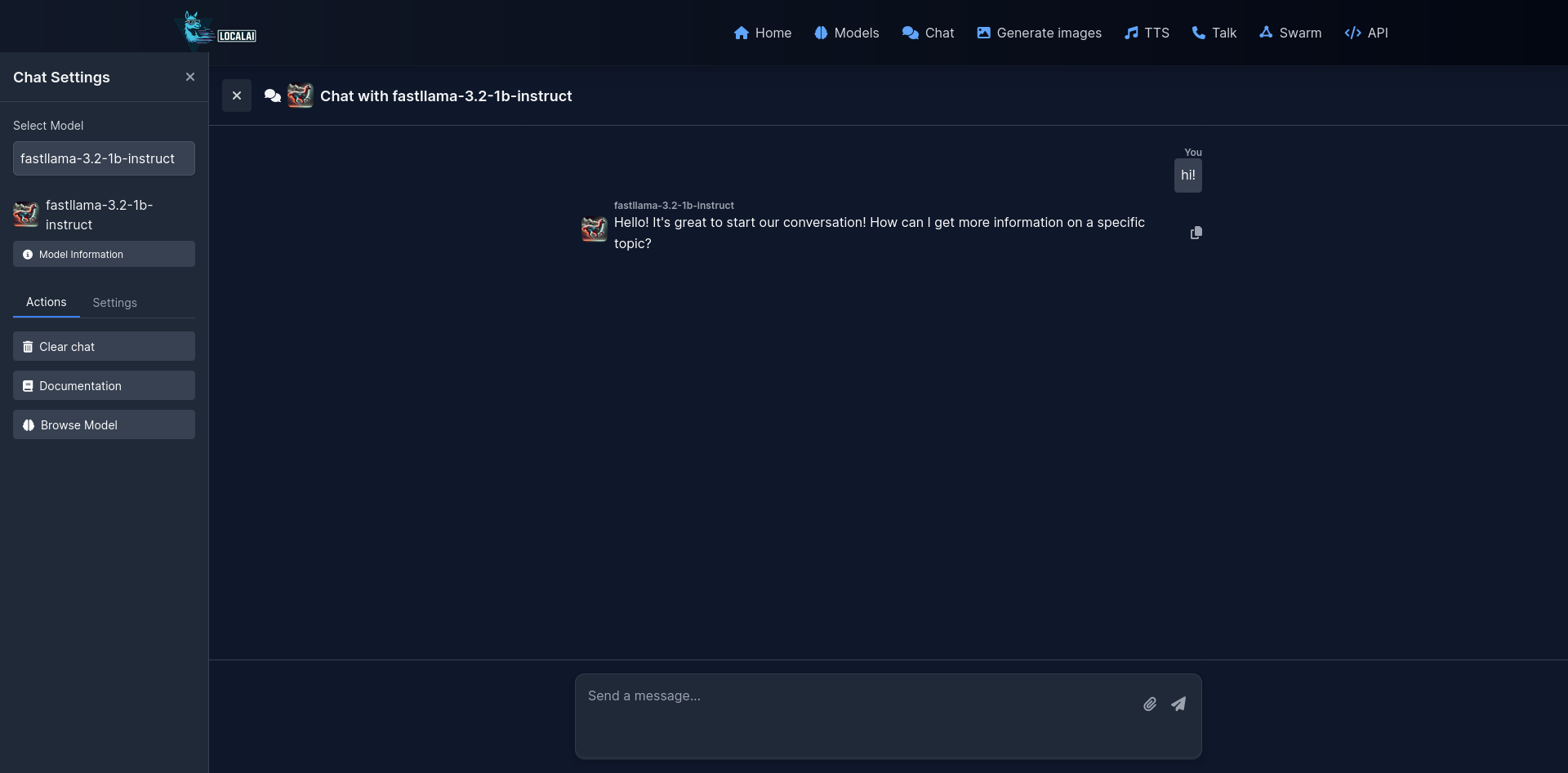 | 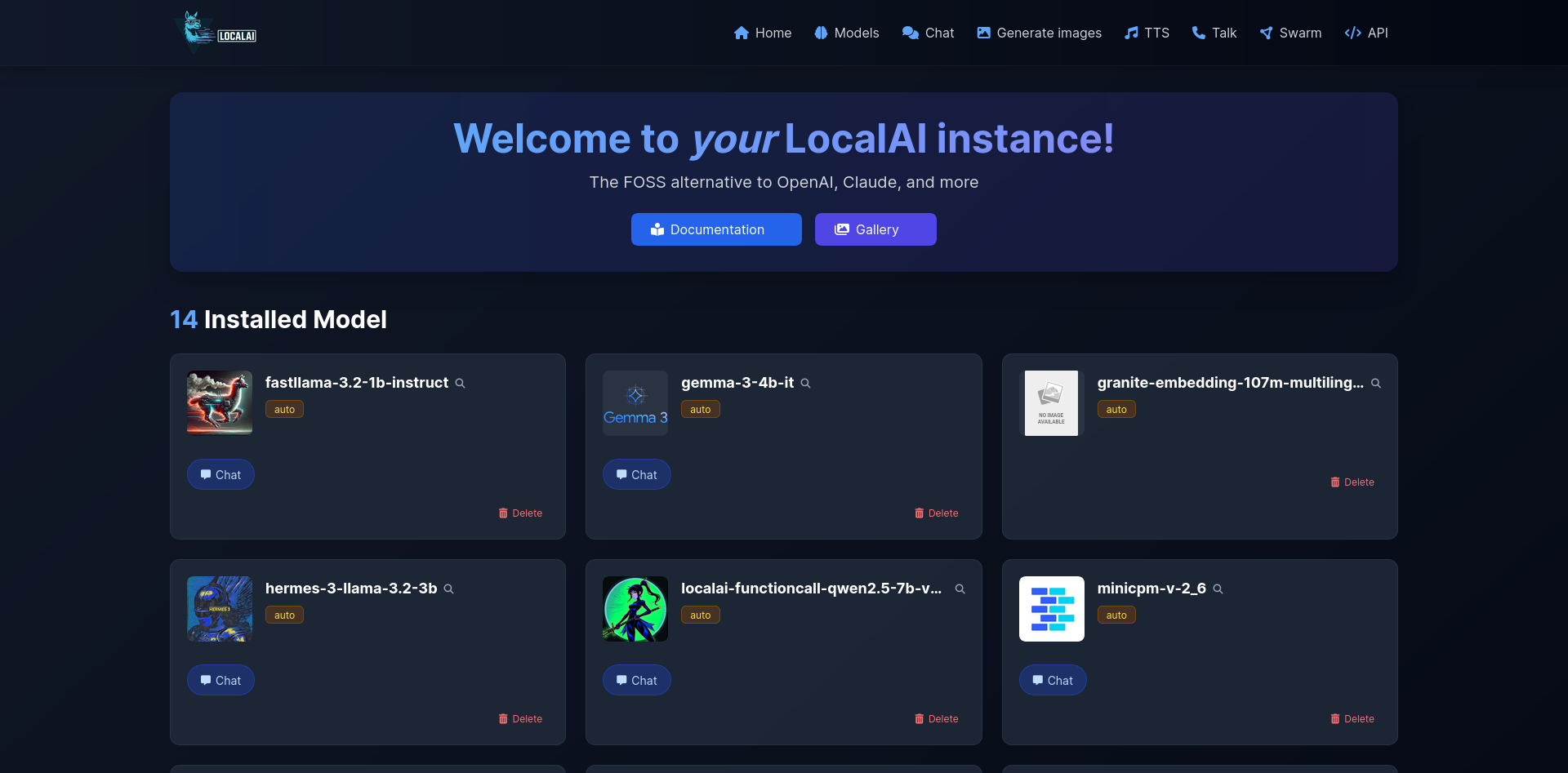 |
| Login | Swarm |
|---|---|
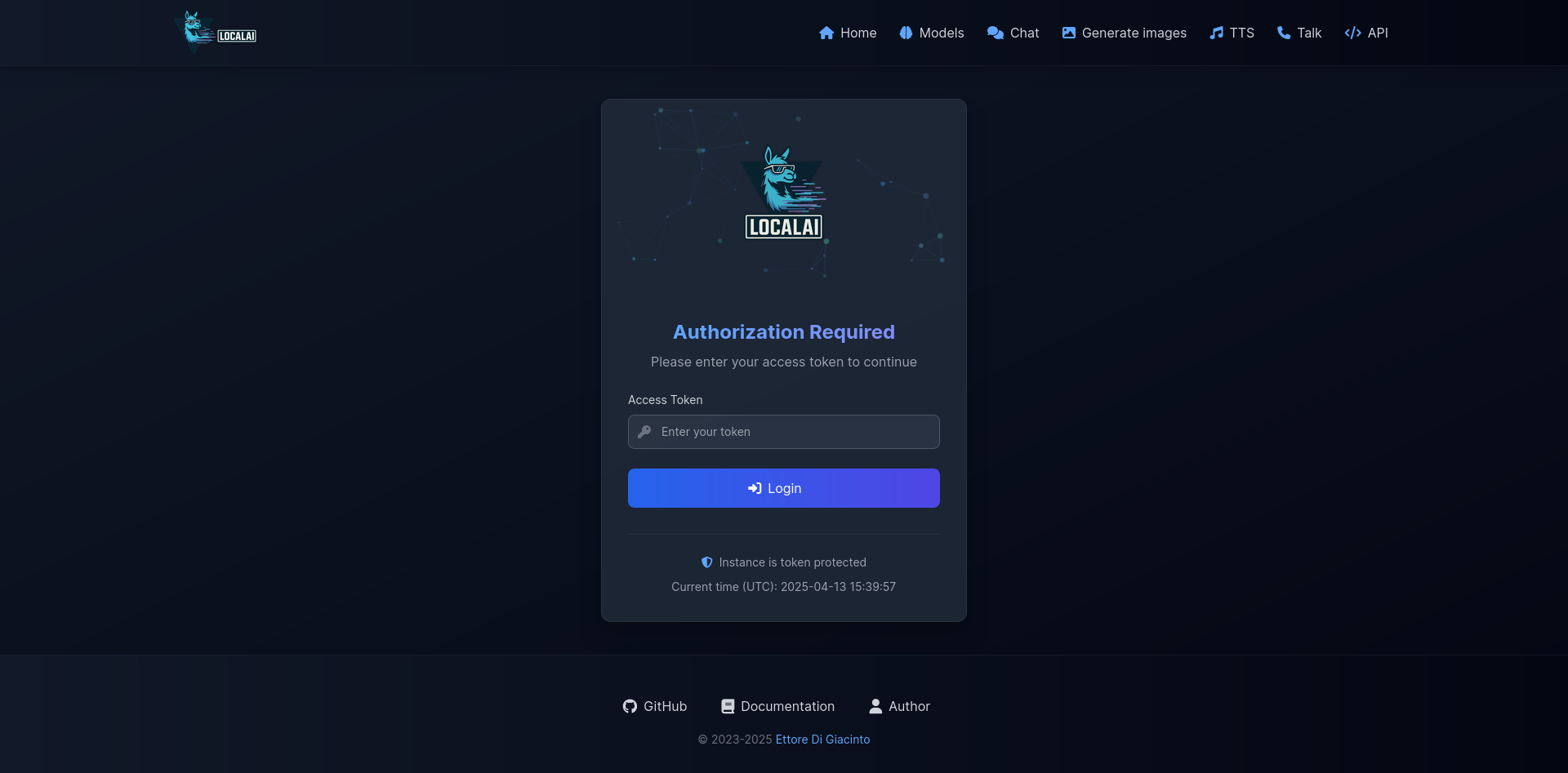 | 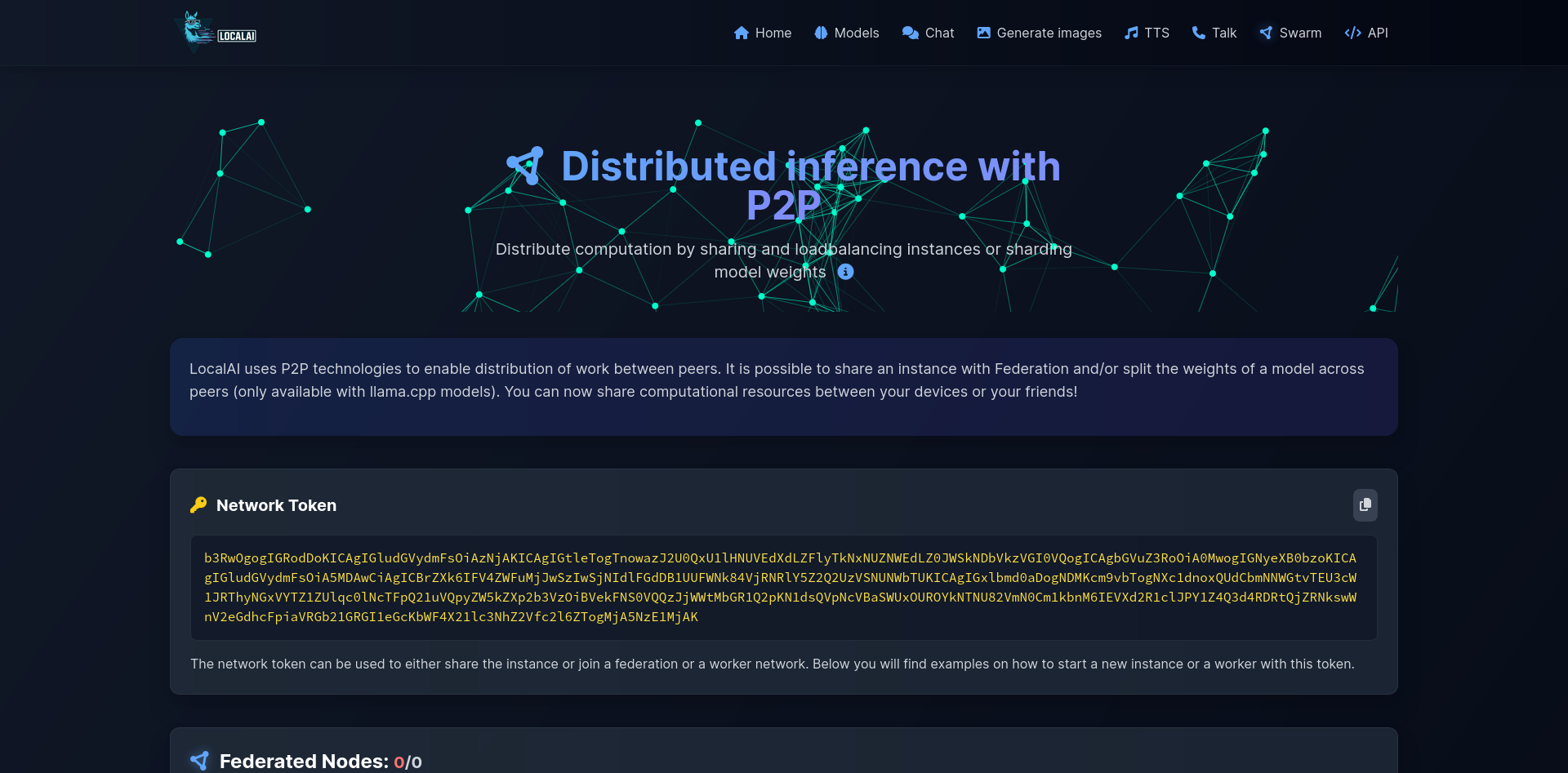 |
💻 Quickstart
Run the installer script:
# Basic installation
curl https://localai.io/install.sh | sh
For more installation options, see Installer Options.
Or run with docker:
CPU only image:
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest
NVIDIA GPU Images:
# CUDA 12.0
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
# CUDA 11.7
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-11
# NVIDIA Jetson (L4T) ARM64
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-nvidia-l4t-arm64
AMD GPU Images (ROCm):
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-gpu-hipblas
Intel GPU Images (oneAPI):
docker run -ti --name local-ai -p 8080:8080 --device=/dev/dri/card1 --device=/dev/dri/renderD128 localai/localai:latest-gpu-intel
Vulkan GPU Images:
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-gpu-vulkan
AIO Images (pre-downloaded models):
# CPU version
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpu
# NVIDIA CUDA 12 version
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-12
# NVIDIA CUDA 11 version
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-11
# Intel GPU version
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-gpu-intel
# AMD GPU version
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-aio-gpu-hipblas
For more information about the AIO images and pre-downloaded models, see Container Documentation.
To load models:
# From the model gallery (see available models with `local-ai models list`, in the WebUI from the model tab, or visiting https://models.localai.io)
local-ai run llama-3.2-1b-instruct:q4_k_m
# Start LocalAI with the phi-2 model directly from huggingface
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
# Install and run a model from the Ollama OCI registry
local-ai run ollama://gemma:2b
# Run a model from a configuration file
local-ai run https://gist.githubusercontent.com/.../phi-2.yaml
# Install and run a model from a standard OCI registry (e.g., Docker Hub)
local-ai run oci://localai/phi-2:latest
⚡ Automatic Backend Detection: When you install models from the gallery or YAML files, LocalAI automatically detects your system's GPU capabilities (NVIDIA, AMD, Intel) and downloads the appropriate backend. For advanced configuration options, see GPU Acceleration.
For more information, see 💻 Getting started
📰 Latest project news
- August 2025: MLX, MLX-VLM, Diffusers and llama.cpp are now supported on Mac M1/M2/M3+ chips ( with
developmentsuffix in the gallery ): https://github.com/mudler/LocalAI/pull/6049 https://github.com/mudler/LocalAI/pull/6119 https://github.com/mudler/LocalAI/pull/6121 https://github.com/mudler/LocalAI/pull/6060 - July/August 2025: 🔍 Object Detection added to the API featuring rf-detr
- July 2025: All backends migrated outside of the main binary. LocalAI is now more lightweight, small, and automatically downloads the required backend to run the model. Read the release notes
- June 2025: Backend management has been added. Attention: extras images are going to be deprecated from the next release! Read the backend management PR.
- May 2025: Audio input and Reranking in llama.cpp backend, Realtime API, Support to Gemma, SmollVLM, and more multimodal models (available in the gallery).
- May 2025: Important: image name changes See release
- Apr 2025: Rebrand, WebUI enhancements
- Apr 2025: LocalAGI and LocalRecall join the LocalAI family stack.
- Apr 2025: WebUI overhaul, AIO images updates
- Feb 2025: Backend cleanup, Breaking changes, new backends (kokoro, OutelTTS, faster-whisper), Nvidia L4T images
- Jan 2025: LocalAI model release: https://huggingface.co/mudler/LocalAI-functioncall-phi-4-v0.3, SANA support in diffusers: https://github.com/mudler/LocalAI/pull/4603
- Dec 2024: stablediffusion.cpp backend (ggml) added ( https://github.com/mudler/LocalAI/pull/4289 )
- Nov 2024: Bark.cpp backend added ( https://github.com/mudler/LocalAI/pull/4287 )
- Nov 2024: Voice activity detection models (VAD) added to the API: https://github.com/mudler/LocalAI/pull/4204
- Oct 2024: examples moved to LocalAI-examples
- Aug 2024: 🆕 FLUX-1, P2P Explorer
- July 2024: 🔥🔥 🆕 P2P Dashboard, LocalAI Federated mode and AI Swarms: https://github.com/mudler/LocalAI/pull/2723. P2P Global community pools: https://github.com/mudler/LocalAI/issues/3113
- May 2024: 🔥🔥 Decentralized P2P llama.cpp: https://github.com/mudler/LocalAI/pull/2343 (peer2peer llama.cpp!) 👉 Docs https://localai.io/features/distribute/
- May 2024: 🔥🔥 Distributed inferencing: https://github.com/mudler/LocalAI/pull/2324
- April 2024: Reranker API: https://github.com/mudler/LocalAI/pull/2121
Roadmap items: List of issues
🚀 Features
- 🧩 Backend Gallery: Install/remove backends on the fly, powered by OCI images — fully customizable and API-driven.
- 📖 Text generation with GPTs (
llama.cpp,transformers,vllm... :book: and more) - 🗣 Text to Audio
- 🔈 Audio to Text (Audio transcription with
whisper.cpp) - 🎨 Image generation
- 🔥 OpenAI-alike tools API
- 🧠 Embeddings generation for vector databases
- ✍️ Constrained grammars
- 🖼️ Download Models directly from Huggingface
- 🥽 Vision API
- 🔍 Object Detection
- 📈 Reranker API
- 🆕🖧 P2P Inferencing
- Agentic capabilities
- 🔊 Voice activity detection (Silero-VAD support)
- 🌍 Integrated WebUI!
🧩 Supported Backends & Acceleration
LocalAI supports a comprehensive range of AI backends with multiple acceleration options:
Text Generation & Language Models
| Backend | Description | Acceleration Support |
|---|---|---|
| llama.cpp | LLM inference in C/C++ | CUDA 11/12, ROCm, Intel SYCL, Vulkan, Metal, CPU |
| vLLM | Fast LLM inference with PagedAttention | CUDA 12, ROCm, Intel |
| transformers | HuggingFace transformers framework | CUDA 11/12, ROCm, Intel, CPU |
| exllama2 | GPTQ inference library | CUDA 12 |
| MLX | Apple Silicon LLM inference | Metal (M1/M2/M3+) |
| MLX-VLM | Apple Silicon Vision-Language Models | Metal (M1/M2/M3+) |
Audio & Speech Processing
| Backend | Description | Acceleration Support |
|---|---|---|
| whisper.cpp | OpenAI Whisper in C/C++ | CUDA 12, ROCm, Intel SYCL, Vulkan, CPU |
| faster-whisper | Fast Whisper with CTranslate2 | CUDA 12, ROCm, Intel, CPU |
| bark | Text-to-audio generation | CUDA 12, ROCm, Intel |
| bark-cpp | C++ implementation of Bark | CUDA, Metal, CPU |
| coqui | Advanced TTS with 1100+ languages | CUDA 12, ROCm, Intel, CPU |
| kokoro | Lightweight TTS model | CUDA 12, ROCm, Intel, CPU |
| chatterbox | Production-grade TTS | CUDA 11/12, CPU |
| piper | Fast neural TTS system | CPU |
| kitten-tts | Kitten TTS models | CPU |
| silero-vad | Voice Activity Detection | CPU |
Image & Video Generation
| Backend | Description | Acceleration Support |
|---|---|---|
| stablediffusion.cpp | Stable Diffusion in C/C++ | CUDA 12, Intel SYCL, Vulkan, CPU |
| diffusers | HuggingFace diffusion models | CUDA 11/12, ROCm, Intel, Metal, CPU |
Specialized AI Tasks
| Backend | Description | Acceleration Support |
|---|---|---|
| rfdetr | Real-time object detection | CUDA 12, Intel, CPU |
| rerankers | Document reranking API | CUDA 11/12, ROCm, Intel, CPU |
| local-store | Vector database | CPU |
| huggingface | HuggingFace API integration | API-based |
Hardware Acceleration Matrix
| Acceleration Type | Supported Backends | Hardware Support |
|---|---|---|
| NVIDIA CUDA 11 | llama.cpp, whisper, stablediffusion, diffusers, rerankers, bark, chatterbox | Nvidia hardware |
| NVIDIA CUDA 12 | All CUDA-compatible backends | Nvidia hardware |
| AMD ROCm | llama.cpp, whisper, vllm, transformers, diffusers, rerankers, coqui, kokoro, bark | AMD Graphics |
| Intel oneAPI | llama.cpp, whisper, stablediffusion, vllm, transformers, diffusers, rfdetr, rerankers, exllama2, coqui, kokoro, bark | Intel Arc, Intel iGPUs |
| Apple Metal | llama.cpp, whisper, diffusers, MLX, MLX-VLM, bark-cpp | Apple M1/M2/M3+ |
| Vulkan | llama.cpp, whisper, stablediffusion | Cross-platform GPUs |
| NVIDIA Jetson | llama.cpp, whisper, stablediffusion, diffusers, rfdetr | ARM64 embedded AI |
| CPU Optimized | All backends | AVX/AVX2/AVX512, quantization support |
🔗 Community and integrations
Build and deploy custom containers:
WebUIs:
- https://github.com/Jirubizu/localai-admin
- https://github.com/go-skynet/LocalAI-frontend
- QA-Pilot(An interactive chat project that leverages LocalAI LLMs for rapid understanding and navigation of GitHub code repository) https://github.com/reid41/QA-Pilot
Model galleries
Other:
- Helm chart https://github.com/go-skynet/helm-charts
- VSCode extension https://github.com/badgooooor/localai-vscode-plugin
- Langchain: https://python.langchain.com/docs/integrations/providers/localai/
- Terminal utility https://github.com/djcopley/ShellOracle
- Local Smart assistant https://github.com/mudler/LocalAGI
- Home Assistant https://github.com/sammcj/homeassistant-localai / https://github.com/drndos/hass-openai-custom-conversation / https://github.com/valentinfrlch/ha-gpt4vision
- Discord bot https://github.com/mudler/LocalAGI/tree/main/examples/discord
- Slack bot https://github.com/mudler/LocalAGI/tree/main/examples/slack
- Shell-Pilot(Interact with LLM using LocalAI models via pure shell scripts on your Linux or MacOS system) https://github.com/reid41/shell-pilot
- Telegram bot https://github.com/mudler/LocalAI/tree/master/examples/telegram-bot
- Another Telegram Bot https://github.com/JackBekket/Hellper
- Auto-documentation https://github.com/JackBekket/Reflexia
- Github bot which answer on issues, with code and documentation as context https://github.com/JackBekket/GitHelper
- Github Actions: https://github.com/marketplace/actions/start-localai
- Examples: https://github.com/mudler/LocalAI/tree/master/examples/
🔗 Resources
- LLM finetuning guide
- How to build locally
- How to install in Kubernetes
- Projects integrating LocalAI
- How tos section (curated by our community)
:book: 🎥 Media, Blogs, Social
- Run Visual studio code with LocalAI (SUSE)
- 🆕 Run LocalAI on Jetson Nano Devkit
- Run LocalAI on AWS EKS with Pulumi
- Run LocalAI on AWS
- Create a slackbot for teams and OSS projects that answer to documentation
- LocalAI meets k8sgpt
- Question Answering on Documents locally with LangChain, LocalAI, Chroma, and GPT4All
- Tutorial to use k8sgpt with LocalAI
Citation
If you utilize this repository, data in a downstream project, please consider citing it with:
@misc{localai,
author = {Ettore Di Giacinto},
title = {LocalAI: The free, Open source OpenAI alternative},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/go-skynet/LocalAI}},
❤️ Sponsors
Do you find LocalAI useful?
Support the project by becoming a backer or sponsor. Your logo will show up here with a link to your website.
A huge thank you to our generous sponsors who support this project covering CI expenses, and our Sponsor list:
🌟 Star history
📖 License
LocalAI is a community-driven project created by Ettore Di Giacinto.
MIT - Author Ettore Di Giacinto [email protected]
🙇 Acknowledgements
LocalAI couldn't have been built without the help of great software already available from the community. Thank you!
- llama.cpp
- https://github.com/tatsu-lab/stanford_alpaca
- https://github.com/cornelk/llama-go for the initial ideas
- https://github.com/antimatter15/alpaca.cpp
- https://github.com/EdVince/Stable-Diffusion-NCNN
- https://github.com/ggerganov/whisper.cpp
- https://github.com/rhasspy/piper
🤗 Contributors
This is a community project, a special thanks to our contributors! 🤗
Discover Repositories
Search across tracked repositories by name or description