microsoft/VibeVoice
Open-Source Frontier Voice AI
Backblaze Generative Media Hackathon
Build the next generation of AI media apps with Genblaze, stored on Backblaze B2. $10,000 in prizes.
Loading star history...
Use Cases & Benefits
- Generates expressive, long-form, multi-speaker conversational speech from text using advanced voice AI techniques.
- Enables scalable, natural-sounding speech synthesis with consistent speaker identity and real-time low-latency streaming capabilities.
- Use for creating multi-speaker podcasts or audiobooks with natural turn-taking and extended dialogue length.
- Use for building real-time text-to-speech applications requiring streaming input and fast initial audio output.
- Use for research and development in speech synthesis focusing on multi-lingual, multi-speaker conversational AI models.
About VibeVoice
🎙️ VibeVoice: Open-Source Frontier Voice AI
📰 News
2025-12-03: 📣 We open-sourced VibeVoice‑Realtime‑0.5B, a real‑time text‑to‑speech model that supports streaming text input and robust long-form speech generation. Try it on Colab.
To mitigate deepfake risks and ensure low latency for the first speech chunk, voice prompts are provided in an embedded format. For users requiring voice customization, please reach out to our team. We will also be expanding the range of available speakers.
https://github.com/user-attachments/assets/0901d274-f6ae-46ef-a0fd-3c4fba4f76dc
(Launch your own realtime demo via the websocket example in Usage).
2025-09-05: VibeVoice is an open-source research framework intended to advance collaboration in the speech synthesis community. After release, we discovered instances where the tool was used in ways inconsistent with the stated intent. Since responsible use of AI is one of Microsoft’s guiding principles, we have disabled this repo until we are confident that out-of-scope use is no longer possible.
Overview
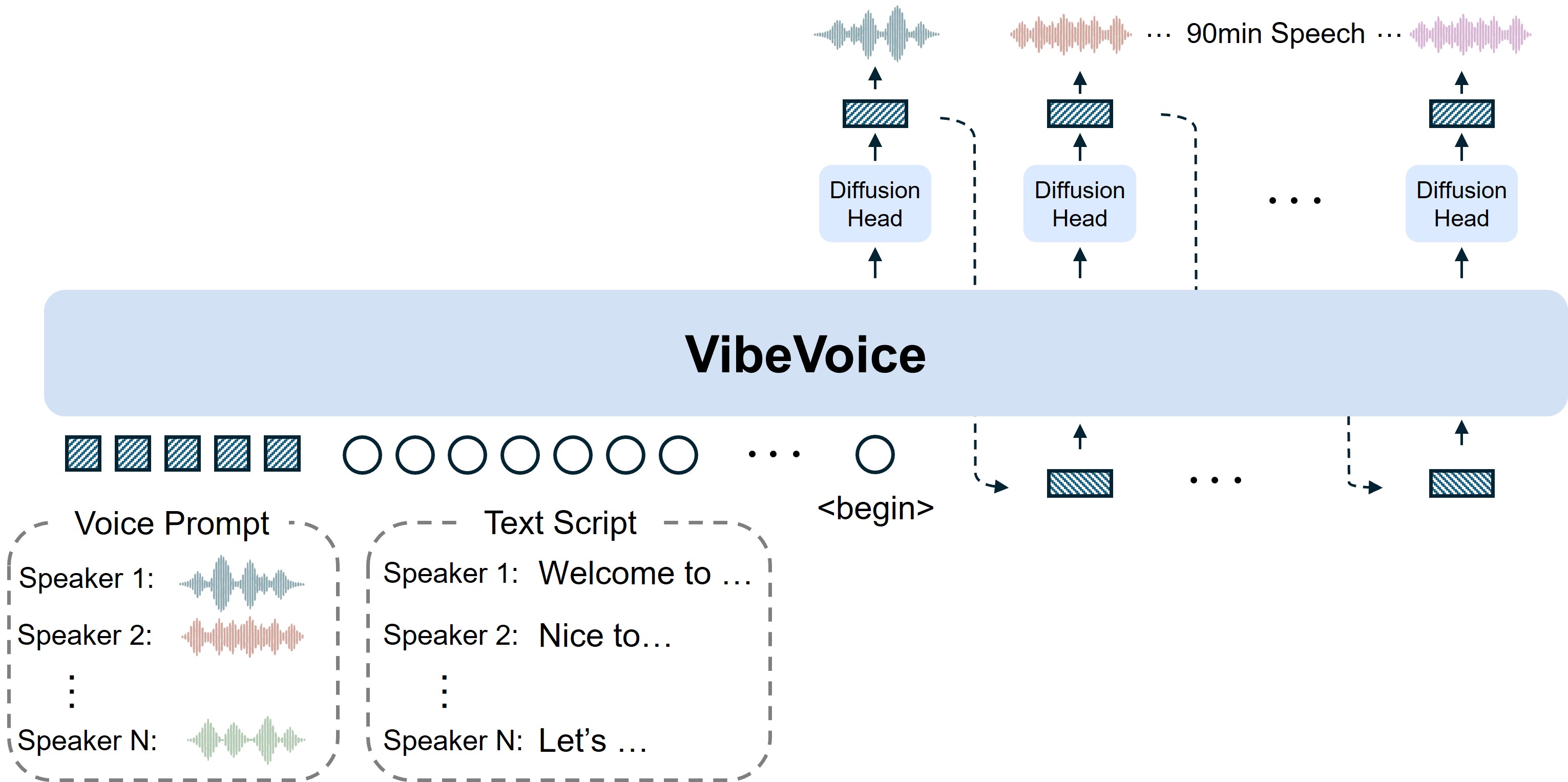
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking.
VibeVoice currently includes two model variants:
- Long-form multi-speaker model: Synthesizes conversational/single-speaker speech up to 90 minutes with up to 4 distinct speakers, surpassing the typical 1–2 speaker limits of many prior models.
- Realtime streaming TTS model: Produces initial audible speech in ~300 ms and supports streaming text input for single-speaker real-time speech generation; designed for low-latency generation.
A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details.
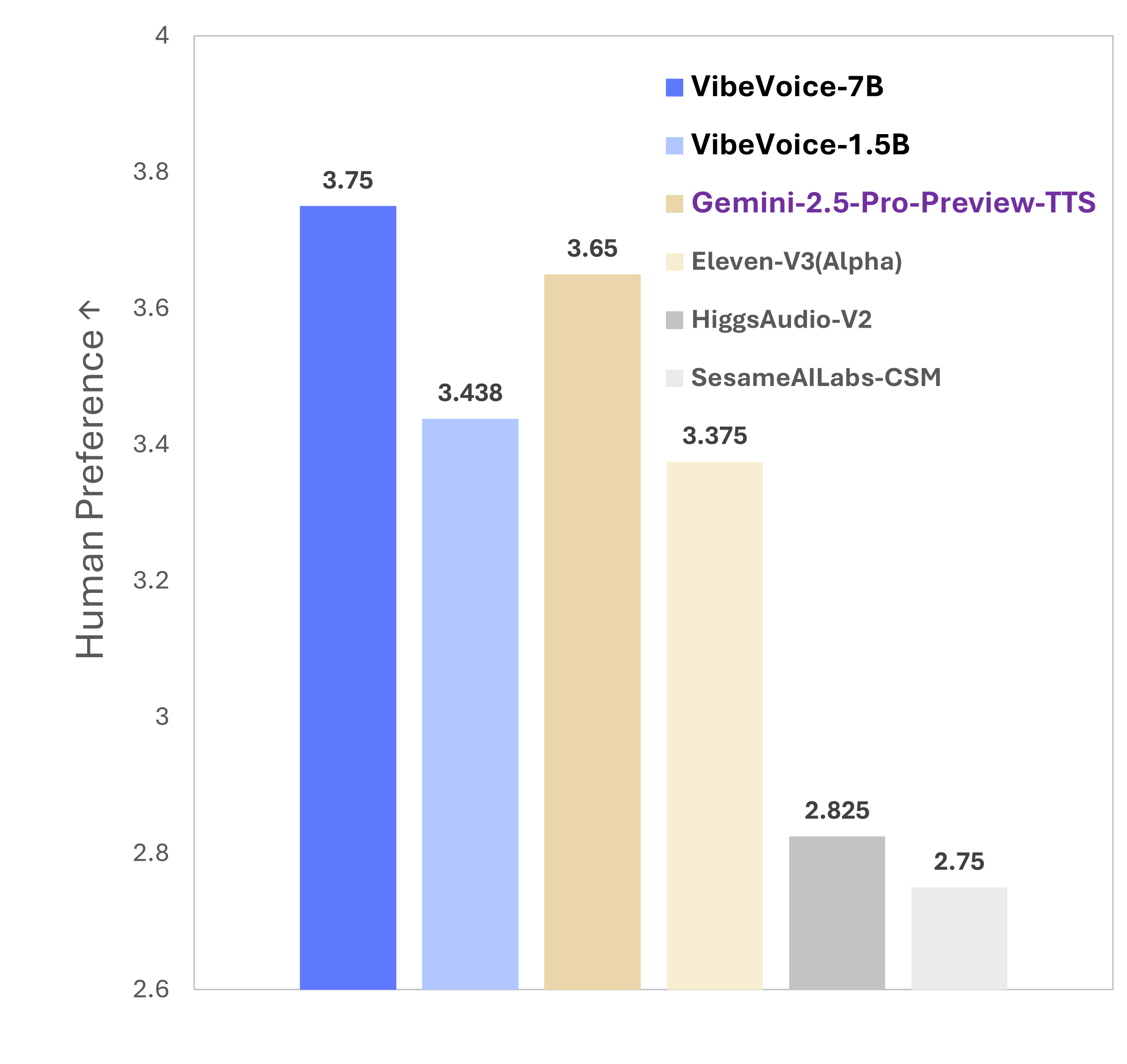
🎵 Demo Examples
Video Demo
We produced this video with Wan2.2. We sincerely appreciate the Wan-Video team for their great work.
English
Chinese
Cross-Lingual
Spontaneous Singing
Long Conversation with 4 people
For more examples, see the Project Page.
Risks and limitations
While efforts have been made to optimize it through various techniques, it may still produce outputs that are unexpected, biased, or inaccurate. VibeVoice inherits any biases, errors, or omissions produced by its base model (specifically, Qwen2.5 1.5b in this release). Potential for Deepfakes and Disinformation: High-quality synthetic speech can be misused to create convincing fake audio content for impersonation, fraud, or spreading disinformation. Users must ensure transcripts are reliable, check content accuracy, and avoid using generated content in misleading ways. Users are expected to use the generated content and to deploy the models in a lawful manner, in full compliance with all applicable laws and regulations in the relevant jurisdictions. It is best practice to disclose the use of AI when sharing AI-generated content.
English and Chinese only: Transcripts in languages other than English or Chinese may result in unexpected audio outputs.
Non-Speech Audio: The model focuses solely on speech synthesis and does not handle background noise, music, or other sound effects.
Overlapping Speech: The current model does not explicitly model or generate overlapping speech segments in conversations.
We do not recommend using VibeVoice in commercial or real-world applications without further testing and development. This model is intended for research and development purposes only. Please use responsibly.
Discover Repositories
Search across tracked repositories by name or description