
fishaudio/fish-speech
SOTA Open Source TTS

Loading star history...
Health Score
24.01
Weekly Growth
+46
+0.2% this week
Contributors
1
Total contributors
Open Issues
24
Generated Insights
About fish-speech



[!IMPORTANT] License Notice
This codebase is released under Apache License and all model weights are released under CC-BY-NC-SA-4.0 License. Please refer to LICENSE for more details.
[!WARNING] Legal Disclaimer
We do not hold any responsibility for any illegal usage of the codebase. Please refer to your local laws about DMCA and other related laws.
Start Here
Here are the official documents for Fish Speech, follow the instructions to get started easily.
🎉 Announcement
We are excited to announce that we have rebranded to OpenAudio — introducing a revolutionary new series of advanced Text-to-Speech models that builds upon the foundation of Fish-Speech.
We are proud to release OpenAudio-S1 as the first model in this series, delivering significant improvements in quality, performance, and capabilities.
OpenAudio-S1 comes in two versions: OpenAudio-S1 and OpenAudio-S1-mini. Both models are now available on Fish Audio Playground (for OpenAudio-S1) and Hugging Face (for OpenAudio-S1-mini).
Visit the OpenAudio website for blog & tech report.
Highlights ✨
Excellent TTS quality
We use Seed TTS Eval Metrics to evaluate the model performance, and the results show that OpenAudio S1 achieves 0.008 WER and 0.004 CER on English text, which is significantly better than previous models. (English, auto eval, based on OpenAI gpt-4o-transcribe, speaker distance using Revai/pyannote-wespeaker-voxceleb-resnet34-LM)
| Model | Word Error Rate (WER) | Character Error Rate (CER) | Speaker Distance |
|---|---|---|---|
| S1 | 0.008 | 0.004 | 0.332 |
| S1-mini | 0.011 | 0.005 | 0.380 |
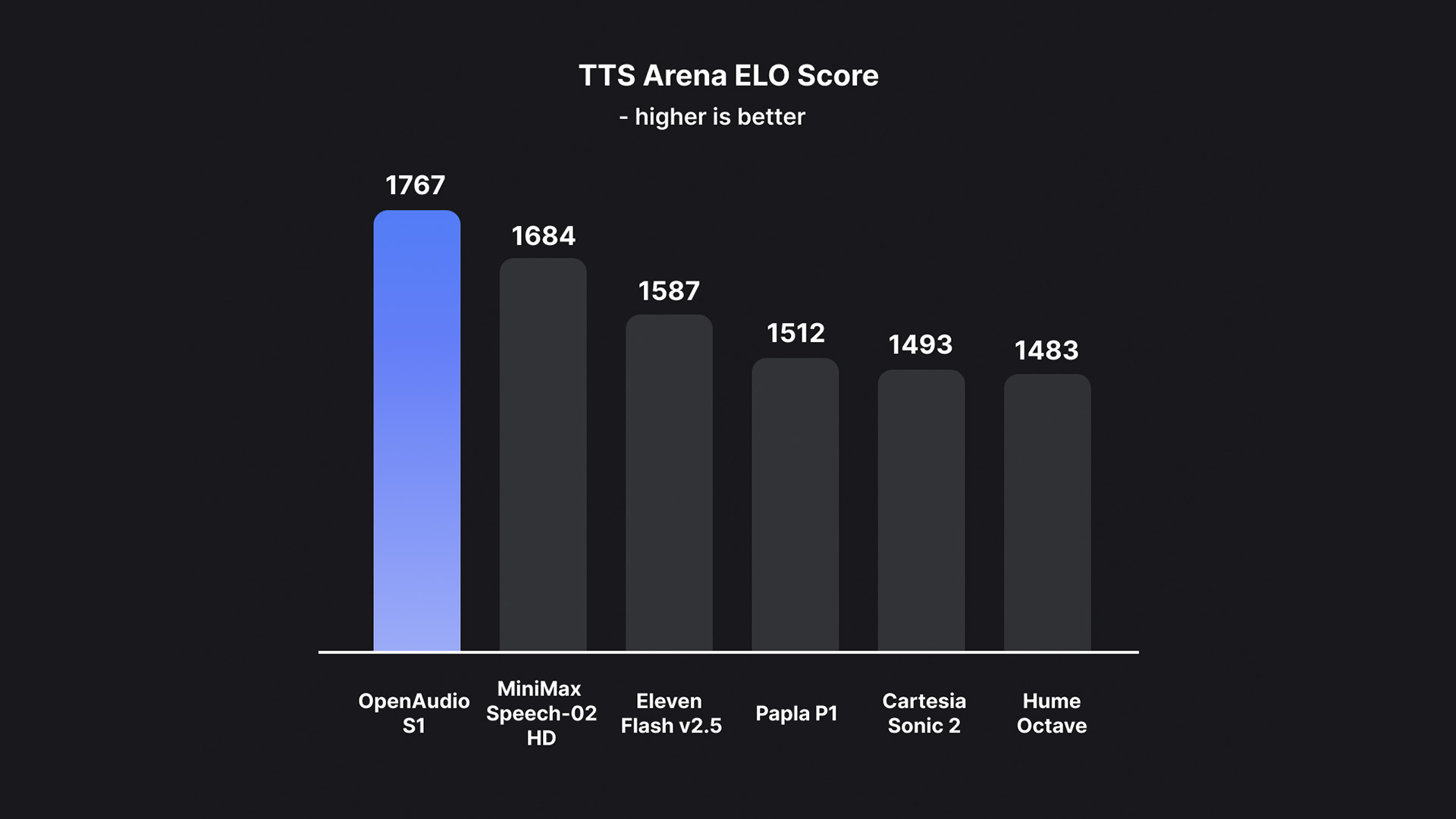
Best Model in TTS-Arena2 🏆
OpenAudio S1 has achieved the #1 ranking on TTS-Arena2, the benchmark for text-to-speech evaluation:
Speech Control
OpenAudio S1 supports a variety of emotional, tone, and special markers to enhance speech synthesis:
- Basic emotions:
(angry) (sad) (excited) (surprised) (satisfied) (delighted)
(scared) (worried) (upset) (nervous) (frustrated) (depressed)
(empathetic) (embarrassed) (disgusted) (moved) (proud) (relaxed)
(grateful) (confident) (interested) (curious) (confused) (joyful)
- Advanced emotions:
(disdainful) (unhappy) (anxious) (hysterical) (indifferent)
(impatient) (guilty) (scornful) (panicked) (furious) (reluctant)
(keen) (disapproving) (negative) (denying) (astonished) (serious)
(sarcastic) (conciliative) (comforting) (sincere) (sneering)
(hesitating) (yielding) (painful) (awkward) (amused)
- Tone markers:
(in a hurry tone) (shouting) (screaming) (whispering) (soft tone)
- Special audio effects:
(laughing) (chuckling) (sobbing) (crying loudly) (sighing) (panting)
(groaning) (crowd laughing) (background laughter) (audience laughing)
You can also use Ha,ha,ha to control, there's many other cases waiting to be explored by yourself.
(Support for English, Chinese and Japanese now, and more languages is coming soon!)
Two Type of Models
| Model | Size | Availability | Features |
|---|---|---|---|
| S1 | 4B parameters | Avaliable on fish.audio | Full-featured flagship model |
| S1-mini | 0.5B parameters | Avaliable on huggingface hf space | Distilled version with core capabilities |
Both S1 and S1-mini incorporate online Reinforcement Learning from Human Feedback (RLHF).
Features
-
Zero-shot & Few-shot TTS: Input a 10 to 30-second vocal sample to generate high-quality TTS output. For detailed guidelines, see Voice Cloning Best Practices.
-
Multilingual & Cross-lingual Support: Simply copy and paste multilingual text into the input box—no need to worry about the language. Currently supports English, Japanese, Korean, Chinese, French, German, Arabic, and Spanish.
-
No Phoneme Dependency: The model has strong generalization capabilities and does not rely on phonemes for TTS. It can handle text in any language script.
-
Highly Accurate: Achieves a low CER (Character Error Rate) of around 0.4% and WER (Word Error Rate) of around 0.8% for Seed-TTS Eval.
-
Fast: Accelerated by torch compile, the real-time factor is approximately 1:7 on an Nvidia RTX 4090 GPU.
-
WebUI Inference: Features an easy-to-use, Gradio-based web UI compatible with Chrome, Firefox, Edge, and other browsers.
-
Deploy-Friendly: Easily set up an inference server with native support for Linux and Windows (macOS support coming soon), minimizing performance loss.
Media & Demos
Social Media
Interactive Demos
Video Showcases

Audio Samples
Credits
Tech Report (V1.4)
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
Discover Repositories
Search across tracked repositories by name or description