eosphoros-ai/DB-GPT
open-source agentic AI data assistant for the next generation of AI + Data products.
Backblaze Generative Media Hackathon
Build the next generation of AI media apps with Genblaze, stored on Backblaze B2. $10,000 in prizes.
Loading star history...
Use Cases & Benefits
- Provides an open-source AI native data app development framework with agentic workflow orchestration and multi-agent collaboration for large model applications with data.
- Enables simplified, low-code creation of bespoke AI and data-driven applications by integrating multi-model management, RAG, fine-tuning, and multi-agent frameworks.
- Use for building private domain Q&A systems and knowledge bases that unify structured and unstructured data with custom data extraction and vector retrieval.
- Use for developing generative business intelligence applications that interact naturally with diverse data sources and generate analytical reports.
- Use for automating Text2SQL fine-tuning workflows to optimize large language models for domain-specific database querying and data analysis.
About DB-GPT
 DB-GPT: AI Native Data App Development framework with AWEL and Agents
DB-GPT: AI Native Data App Development framework with AWEL and Agents
![]()






What is DB-GPT?
🤖 DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents.
The purpose is to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.
🚀 In the Data 3.0 era, based on models and databases, enterprises and developers can build their own bespoke applications with less code.
Introduction
The architecture of DB-GPT is shown in the following figure:
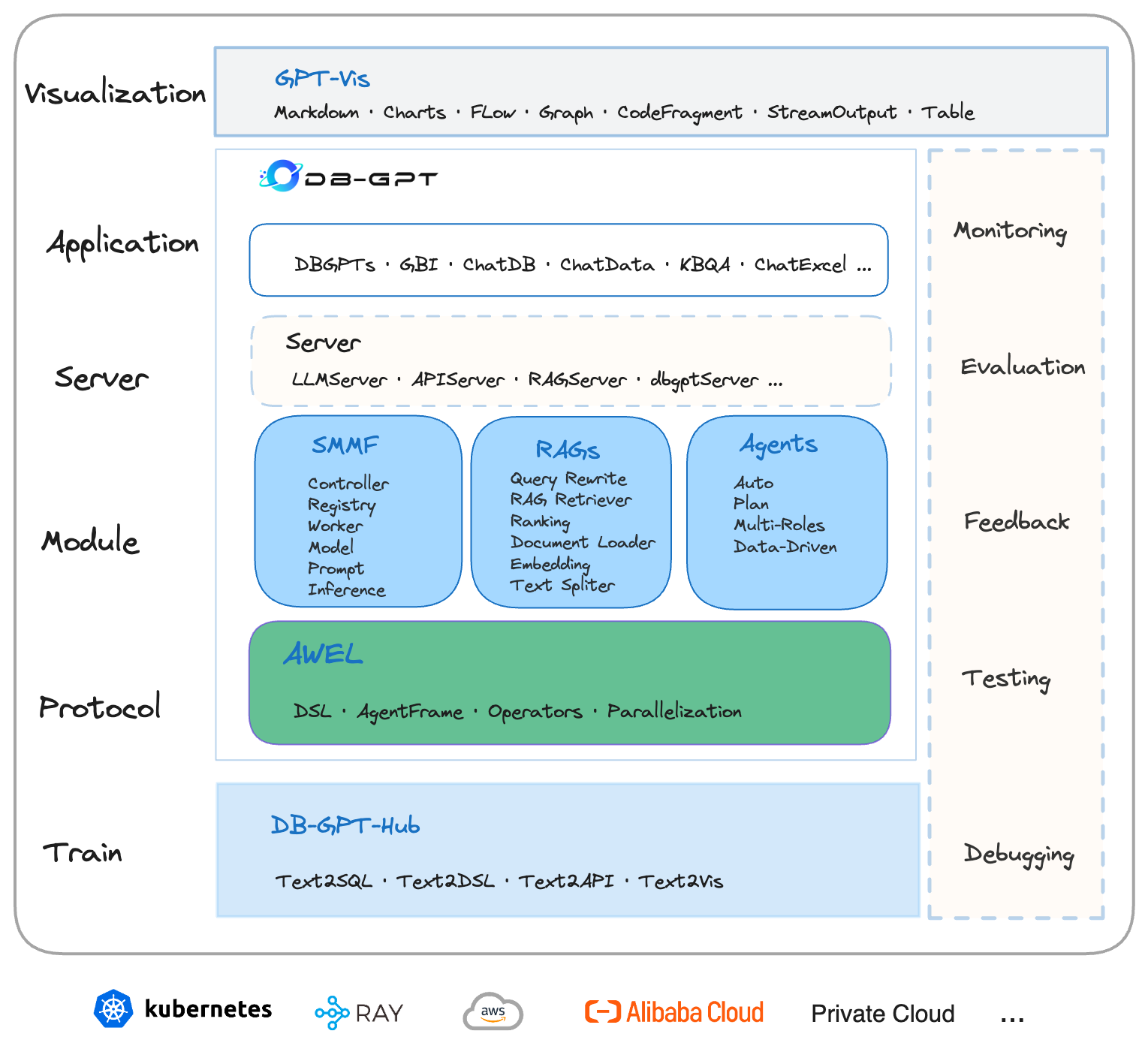
The core capabilities include the following parts:
-
RAG (Retrieval Augmented Generation): RAG is currently the most practically implemented and urgently needed domain. DB-GPT has already implemented a framework based on RAG, allowing users to build knowledge-based applications using the RAG capabilities of DB-GPT.
-
GBI (Generative Business Intelligence): Generative BI is one of the core capabilities of the DB-GPT project, providing the foundational data intelligence technology to build enterprise report analysis and business insights.
-
Fine-tuning Framework: Model fine-tuning is an indispensable capability for any enterprise to implement in vertical and niche domains. DB-GPT provides a complete fine-tuning framework that integrates seamlessly with the DB-GPT project. In recent fine-tuning efforts, an accuracy rate based on the Spider dataset has been achieved at 82.5%.
-
Data-Driven Multi-Agents Framework: DB-GPT offers a data-driven self-evolving multi-agents framework, aiming to continuously make decisions and execute based on data.
-
Data Factory: The Data Factory is mainly about cleaning and processing trustworthy knowledge and data in the era of large models.
-
Data Sources: Integrating various data sources to seamlessly connect production business data to the core capabilities of DB-GPT.
SubModule
-
DB-GPT-Hub Text-to-SQL workflow with high performance by applying Supervised Fine-Tuning (SFT) on Large Language Models (LLMs).
-
dbgpts dbgpts is the official repository which contains some data apps、AWEL operators、AWEL workflow templates and agents which build upon DB-GPT.
Text2SQL Finetune
| LLM | Supported |
|---|---|
| LLaMA | ✅ |
| LLaMA-2 | ✅ |
| BLOOM | ✅ |
| BLOOMZ | ✅ |
| Falcon | ✅ |
| Baichuan | ✅ |
| Baichuan2 | ✅ |
| InternLM | ✅ |
| Qwen | ✅ |
| XVERSE | ✅ |
| ChatGLM2 | ✅ |
More Information about Text2SQL finetune
- DB-GPT-Plugins DB-GPT Plugins that can run Auto-GPT plugin directly
- GPT-Vis Visualization protocol
AI-Native Data App
Installation / Quick Start
![]()
Features
At present, we have introduced several key features to showcase our current capabilities:
-
Private Domain Q&A & Data Processing
The DB-GPT project offers a range of functionalities designed to improve knowledge base construction and enable efficient storage and retrieval of both structured and unstructured data. These functionalities include built-in support for uploading multiple file formats, the ability to integrate custom data extraction plug-ins, and unified vector storage and retrieval capabilities for effectively managing large volumes of information.
-
Multi-Data Source & GBI(Generative Business intelligence)
The DB-GPT project facilitates seamless natural language interaction with diverse data sources, including Excel, databases, and data warehouses. It simplifies the process of querying and retrieving information from these sources, empowering users to engage in intuitive conversations and gain insights. Moreover, DB-GPT supports the generation of analytical reports, providing users with valuable data summaries and interpretations.
-
Multi-Agents&Plugins
It offers support for custom plug-ins to perform various tasks and natively integrates the Auto-GPT plug-in model. The Agents protocol adheres to the Agent Protocol standard.
-
Automated Fine-tuning text2SQL
We've also developed an automated fine-tuning lightweight framework centred on large language models (LLMs), Text2SQL datasets, LoRA/QLoRA/Pturning, and other fine-tuning methods. This framework simplifies Text-to-SQL fine-tuning, making it as straightforward as an assembly line process. DB-GPT-Hub
-
SMMF(Service-oriented Multi-model Management Framework)
We offer extensive model support, including dozens of large language models (LLMs) from both open-source and API agents, such as LLaMA/LLaMA2, Baichuan, ChatGLM, Wenxin, Tongyi, Zhipu, and many more.
-
News
Provider Supported Models DeepSeek ✅ 🔥🔥🔥 DeepSeek-R1-0528
🔥🔥🔥 DeepSeek-V3-0324
🔥��🔥🔥 DeepSeek-R1
🔥🔥🔥 DeepSeek-V3
🔥🔥🔥 DeepSeek-R1-Distill-Llama-70B
🔥🔥🔥 DeepSeek-R1-Distill-Qwen-32B
🔥🔥🔥 DeepSeek-Coder-V2-Instruct
Qwen ✅ 🔥🔥🔥 Qwen3-235B-A22B
🔥🔥🔥 Qwen3-30B-A3B
🔥🔥🔥 Qwen3-32B
🔥🔥🔥 QwQ-32B
🔥🔥🔥 Qwen2.5-Coder-32B-Instruct
🔥🔥🔥 Qwen2.5-Coder-14B-Instruct
🔥🔥🔥 Qwen2.5-72B-Instruct
🔥🔥🔥 Qwen2.5-32B-Instruct
GLM ✅ 🔥🔥🔥 GLM-Z1-32B-0414
🔥🔥🔥 GLM-4-32B-0414
🔥🔥🔥 Glm-4-9b-chatLlama ✅ 🔥🔥🔥 Meta-Llama-3.1-405B-Instruct
🔥🔥🔥 Meta-Llama-3.1-70B-Instruct
🔥🔥🔥 Meta-Llama-3.1-8B-Instruct
🔥🔥🔥 Meta-Llama-3-70B-Instruct
🔥🔥🔥 Meta-Llama-3-8B-InstructGemma ✅ 🔥🔥🔥 gemma-2-27b-it
🔥🔥🔥 gemma-2-9b-it
🔥🔥🔥 gemma-7b-it
🔥🔥🔥 gemma-2b-itYi ✅ 🔥🔥🔥 Yi-1.5-34B-Chat
🔥🔥🔥 Yi-1.5-9B-Chat
🔥🔥🔥 Yi-1.5-6B-Chat
🔥🔥🔥 Yi-34B-ChatStarling ✅ 🔥🔥🔥 Starling-LM-7B-beta SOLAR ✅ 🔥🔥🔥 SOLAR-10.7B Mixtral ✅ 🔥🔥🔥 Mixtral-8x7B Phi ✅ 🔥🔥🔥 Phi-3
-
-
Privacy and Security
We ensure the privacy and security of data through the implementation of various technologies, including privatized large models and proxy desensitization.
-
Support Datasources
Image
Contribution
- To check detailed guidelines for new contributions, please refer how to contribute
Contributors Wall
Licence
The MIT License (MIT)
DISCKAIMER
Citation
If you want to understand the overall architecture of DB-GPT, please cite Paper and Paper
If you want to learn about using DB-GPT for Agent development, please cite the Paper
@article{xue2023dbgpt,
title={DB-GPT: Empowering Database Interactions with Private Large Language Models},
author={Siqiao Xue and Caigao Jiang and Wenhui Shi and Fangyin Cheng and Keting Chen and Hongjun Yang and Zhiping Zhang and Jianshan He and Hongyang Zhang and Ganglin Wei and Wang Zhao and Fan Zhou and Danrui Qi and Hong Yi and Shaodong Liu and Faqiang Chen},
year={2023},
journal={arXiv preprint arXiv:2312.17449},
url={https://arxiv.org/abs/2312.17449}
}
@misc{huang2024romasrolebasedmultiagentdatabase,
title={ROMAS: A Role-Based Multi-Agent System for Database monitoring and Planning},
author={Yi Huang and Fangyin Cheng and Fan Zhou and Jiahui Li and Jian Gong and Hongjun Yang and Zhidong Fan and Caigao Jiang and Siqiao Xue and Faqiang Chen},
year={2024},
eprint={2412.13520},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2412.13520},
}
@inproceedings{xue2024demonstration,
title={Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models},
author={Siqiao Xue and Danrui Qi and Caigao Jiang and Wenhui Shi and Fangyin Cheng and Keting Chen and Hongjun Yang and Zhiping Zhang and Jianshan He and Hongyang Zhang and Ganglin Wei and Wang Zhao and Fan Zhou and Hong Yi and Shaodong Liu and Hongjun Yang and Faqiang Chen},
year={2024},
booktitle = "Proceedings of the VLDB Endowment",
url={https://arxiv.org/abs/2404.10209}
}
Contact Information
Thanks to everyone who has contributed to DB-GPT! Your ideas, code, comments, and even sharing them at events and on social platforms can make DB-GPT better. We are working on building a community, if you have any ideas for building the community, feel free to contact us.
- Github Issues ⭐️:For questions about using GB-DPT, see the CONTRIBUTING.
- Github Discussions ⭐️:Share your experience or unique apps.
- Twitter ⭐️:Please feel free to talk to us.
Discover Repositories
Search across tracked repositories by name or description