PromtEngineer/localGPT
Chat with your documents on your local device using GPT models. No data leaves your device and 100% private.
Backblaze Generative Media Hackathon
Build the next generation of AI media apps with Genblaze, stored on Backblaze B2. $10,000 in prizes.
Loading star history...
Use Cases & Benefits
- LocalGPT enables private, on-device document chat and intelligence using GPT models, ensuring no data leaves the user's machine for maximum privacy.
- Key features include hybrid search (semantic + keyword), late chunking for long context, smart routing between RAG and direct LLM, and multi-format document support.
- Strengths are strong privacy, modular lightweight Python architecture, multi-platform GPU/CPU support, and advanced AI features; limitation includes current primary support for PDF format.
- Organizations can deploy LocalGPT on-premise for secure document querying, integrate via RESTful APIs, and customize AI models and pipelines for production use.
- Ideal use cases include confidential document analysis, internal knowledge bases, research paper summarization, and any scenario requiring private, local AI-powered document interaction.
About localGPT
LocalGPT - Private Document Intelligence Platform




![]()
![]()
![]()
🚀 What is LocalGPT?
LocalGPT is a fully private, on-premise Document Intelligence platform. Ask questions, summarise, and uncover insights from your files with state-of-the-art AI—no data ever leaves your machine.
More than a traditional RAG (Retrieval-Augmented Generation) tool, LocalGPT features a hybrid search engine that blends semantic similarity, keyword matching, and Late Chunking for long-context precision. A smart router automatically selects between RAG and direct LLM answering for every query, while contextual enrichment and sentence-level Context Pruning surface only the most relevant content. An independent verification pass adds an extra layer of accuracy.
The architecture is modular and lightweight—enable only the components you need. With a pure-Python core and minimal dependencies, LocalGPT is simple to deploy, run, and maintain on any infrastructure.The system has minimal dependencies on frameworks and libraries, making it easy to deploy and maintain. The RAG system is pure python and does not require any additional dependencies.
▶️ Video
Watch this video to get started with LocalGPT.
| Home | Create Index | Chat |
|---|---|---|
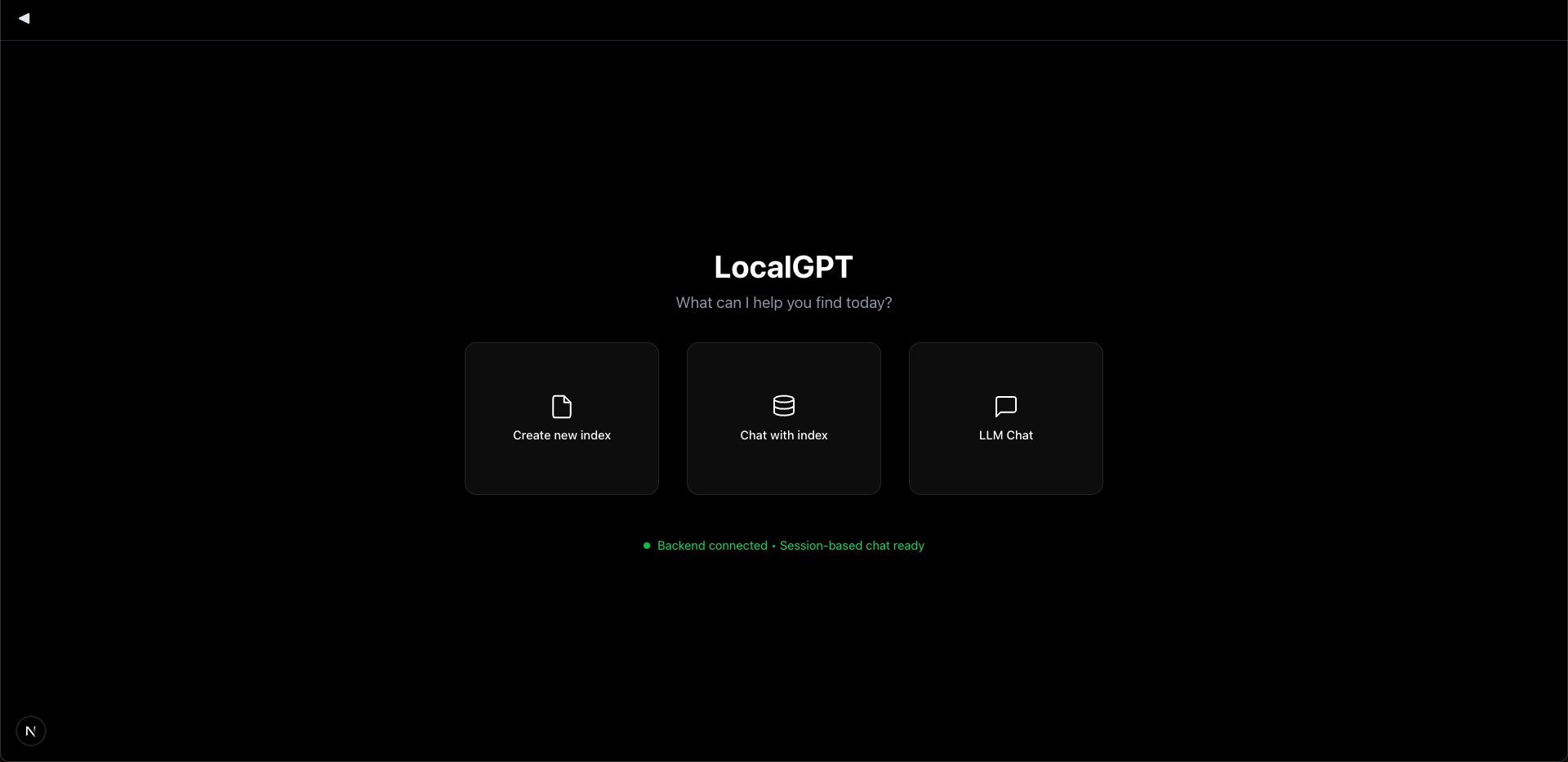 | 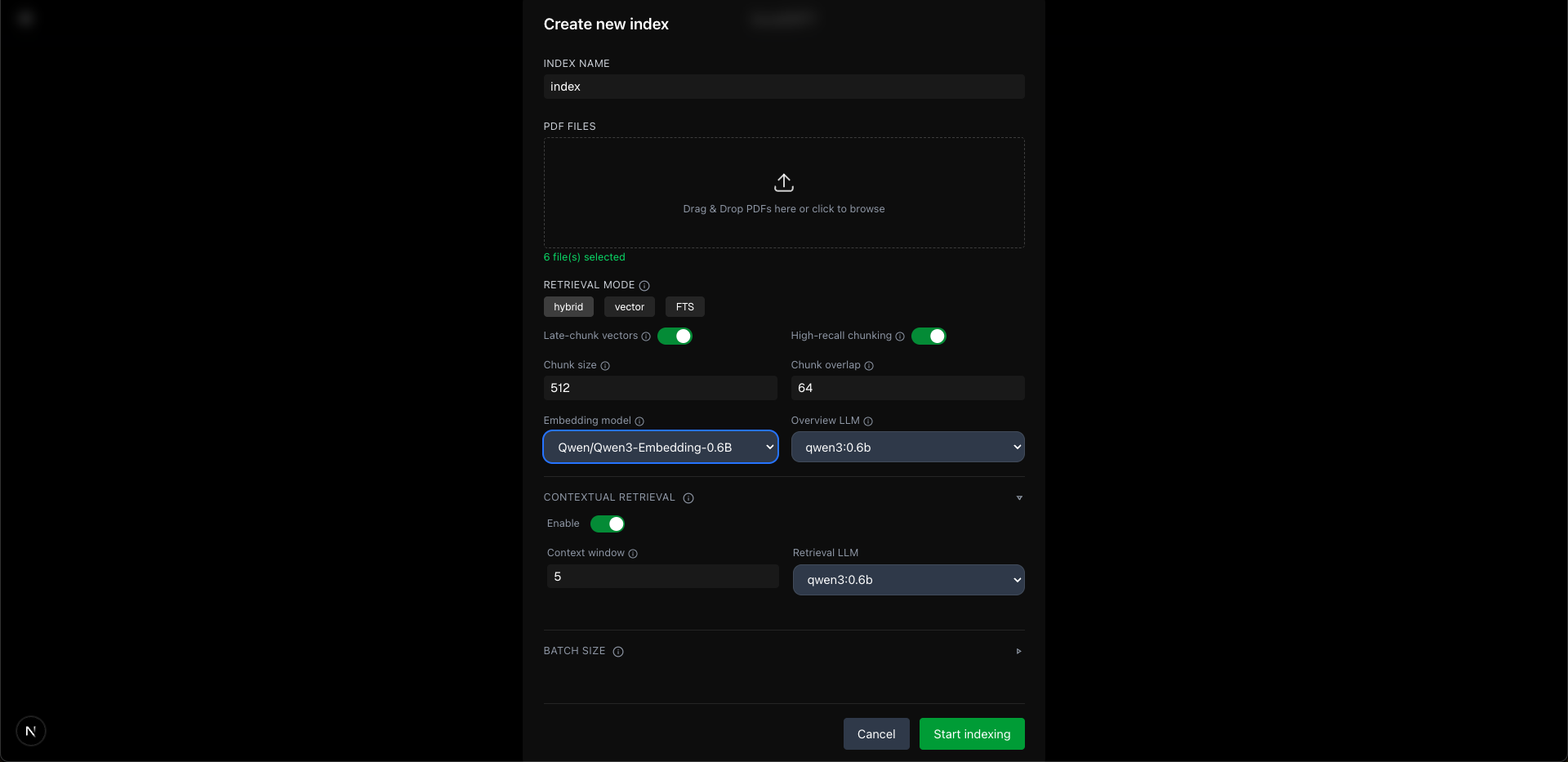 | 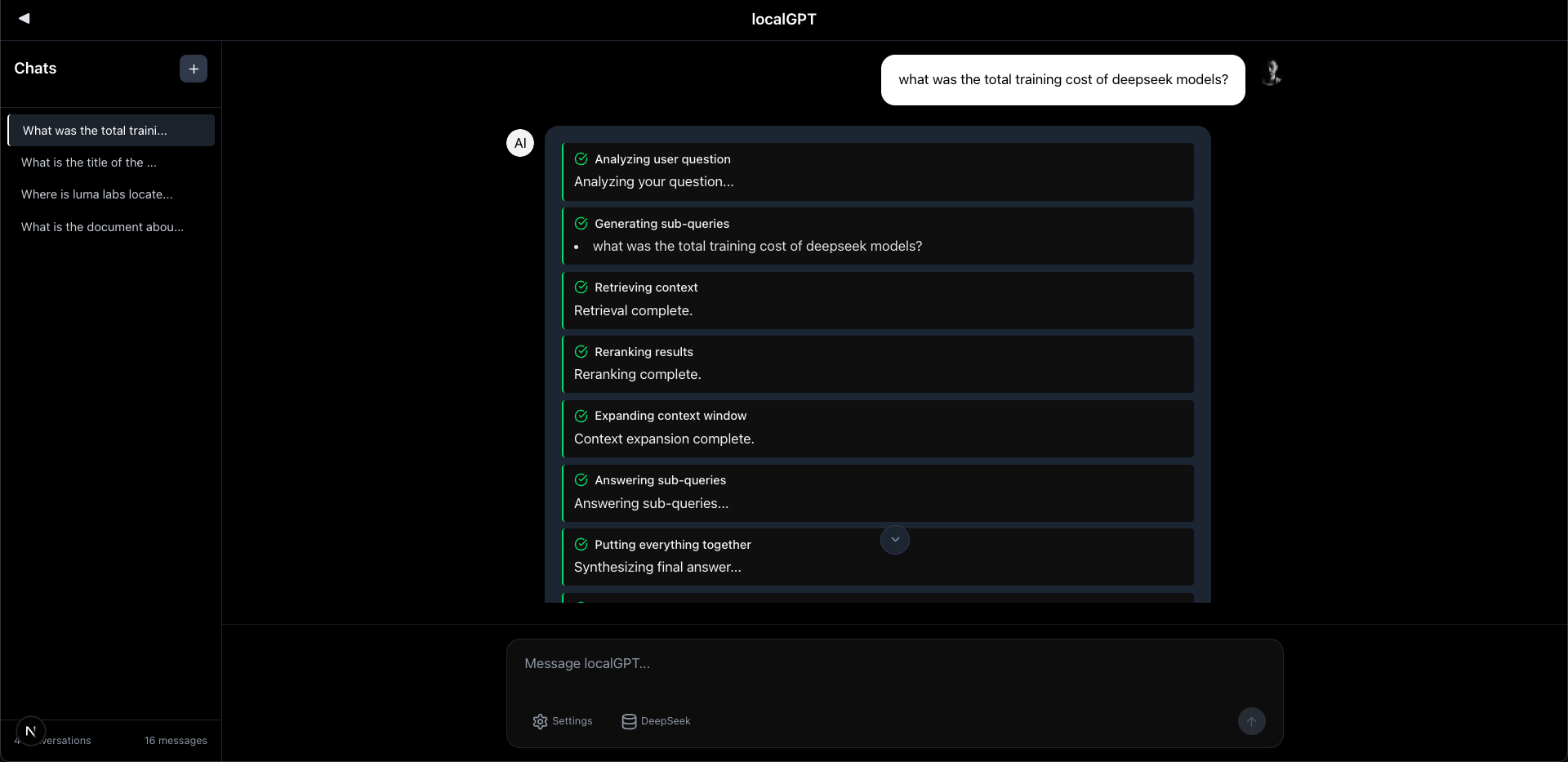 |
✨ Features
- Utmost Privacy: Your data remains on your computer, ensuring 100% security.
- Versatile Model Support: Seamlessly integrate a variety of open-source models via Ollama.
- Diverse Embeddings: Choose from a range of open-source embeddings.
- Reuse Your LLM: Once downloaded, reuse your LLM without the need for repeated downloads.
- Chat History: Remembers your previous conversations (in a session).
- API: LocalGPT has an API that you can use for building RAG Applications.
- GPU, CPU, HPU & MPS Support: Supports multiple platforms out of the box, Chat with your data using
CUDA,CPU,HPU (Intel® Gaudi®)orMPSand more!
📖 Document Processing
- Multi-format Support: PDF, DOCX, TXT, Markdown, and more (Currently only PDF is supported)
- Contextual Enrichment: Enhanced document understanding with AI-generated context, inspired by Contextual Retrieval
- Batch Processing: Handle multiple documents simultaneously
🤖 AI-Powered Chat
- Natural Language Queries: Ask questions in plain English
- Source Attribution: Every answer includes document references
- Smart Routing: Automatically chooses between RAG and direct LLM responses
- Query Decomposition: Breaks complex queries into sub-questions for better answers
- Semantic Caching: TTL-based caching with similarity matching for faster responses
- Session-Aware History: Maintains conversation context across interactions
- Answer Verification: Independent verification pass for accuracy
- Multiple AI Models: Ollama for inference, HuggingFace for embeddings and reranking
🛠️ Developer-Friendly
- RESTful APIs: Complete API access for integration
- Real-time Progress: Live updates during document processing
- Flexible Configuration: Customize models, chunk sizes, and search parameters
- Extensible Architecture: Plugin system for custom components
🎨 Modern Interface
- Intuitive Web UI: Clean, responsive design
- Session Management: Organize conversations by topic
- Index Management: Easy document collection management
- Real-time Chat: Streaming responses for immediate feedback
🚀 Quick Start
Note: The installation is currently only tested on macOS.
Prerequisites
- Python 3.8 or higher (tested with Python 3.11.5)
- Node.js 16+ and npm (tested with Node.js 23.10.0, npm 10.9.2)
- Docker (optional, for containerized deployment)
- 8GB+ RAM (16GB+ recommended)
- Ollama (required for both deployment approaches)
NOTE
Before this brach is moved to the main branch, please clone this branch for instalation:
git clone -b localgpt-v2 https://github.com/PromtEngineer/localGPT.git
cd localGPT
Option 1: Docker Deployment
# Clone the repository
git clone https://github.com/PromtEngineer/localGPT.git
cd localGPT
# Install Ollama locally (required even for Docker)
curl -fsSL https://ollama.ai/install.sh | sh
ollama pull qwen3:0.6b
ollama pull qwen3:8b
# Start Ollama
ollama serve
# Start with Docker (in a new terminal)
./start-docker.sh
# Access the application
open http://localhost:3000
Docker Management Commands:
# Check container status
docker compose ps
# View logs
docker compose logs -f
# Stop containers
./start-docker.sh stop
Option 2: Direct Development (Recommended for Development)
# Clone the repository
git clone https://github.com/PromtEngineer/localGPT.git
cd localGPT
# Install Python dependencies
pip install -r requirements.txt
# Key dependencies installed:
# - torch==2.4.1, transformers==4.51.0 (AI models)
# - lancedb (vector database)
# - rank_bm25, fuzzywuzzy (search algorithms)
# - sentence_transformers, rerankers (embedding/reranking)
# - docling (document processing)
# - colpali-engine (multimodal processing - support coming soon)
# Install Node.js dependencies
npm install
# Install and start Ollama
curl -fsSL https://ollama.ai/install.sh | sh
ollama pull qwen3:0.6b
ollama pull qwen3:8b
ollama serve
# Start the system (in a new terminal)
python run_system.py
# Access the application
open http://localhost:3000
System Management:
# Check system health (comprehensive diagnostics)
python system_health_check.py
# Check service status and health
python run_system.py --health
# Start in production mode
python run_system.py --mode prod
# Skip frontend (backend + RAG API only)
python run_system.py --no-frontend
# View aggregated logs
python run_system.py --logs-only
# Stop all services
python run_system.py --stop
# Or press Ctrl+C in the terminal running python run_system.py
Service Architecture:
The run_system.py launcher manages four key services:
- Ollama Server (port 11434): AI model serving
- RAG API Server (port 8001): Document processing and retrieval
- Backend Server (port 8000): Session management and API endpoints
- Frontend Server (port 3000): React/Next.js web interface
Option 3: Manual Component Startup
# Terminal 1: Start Ollama
ollama serve
# Terminal 2: Start RAG API
python -m rag_system.api_server
# Terminal 3: Start Backend
cd backend && python server.py
# Terminal 4: Start Frontend
npm run dev
# Access at http://localhost:3000
Detailed Installation
1. Install System Dependencies
Ubuntu/Debian:
sudo apt update
sudo apt install python3.8 python3-pip nodejs npm docker.io docker-compose
macOS:
brew install [email protected] node npm docker docker-compose
Windows:
# Install Python 3.8+, Node.js, and Docker Desktop
# Then use PowerShell or WSL2
2. Install AI Models
Install Ollama (Recommended):
# Install Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# Pull recommended models
ollama pull qwen3:0.6b # Fast generation model
ollama pull qwen3:8b # High-quality generation model
3. Configure Environment
# Copy environment template
cp .env.example .env
# Edit configuration
nano .env
Key Configuration Options:
# AI Models (referenced in rag_system/main.py)
OLLAMA_HOST=http://localhost:11434
# Database Paths (used by backend and RAG system)
DATABASE_PATH=./backend/chat_data.db
VECTOR_DB_PATH=./lancedb
# Server Settings (used by run_system.py)
BACKEND_PORT=8000
FRONTEND_PORT=3000
RAG_API_PORT=8001
# Optional: Override default models
GENERATION_MODEL=qwen3:8b
ENRICHMENT_MODEL=qwen3:0.6b
EMBEDDING_MODEL=Qwen/Qwen3-Embedding-0.6B
RERANKER_MODEL=answerdotai/answerai-colbert-small-v1
4. Initialize the System
# Run system health check
python system_health_check.py
# Initialize databases
python -c "from backend.database import ChatDatabase; ChatDatabase().init_database()"
# Test installation
python -c "from rag_system.main import get_agent; print('✅ Installation successful!')"
# Validate complete setup
python run_system.py --health
🎯 Getting Started
1. Create Your First Index
An index is a collection of processed documents that you can chat with.
Using the Web Interface:
- Open http://localhost:3000
- Click "Create New Index"
- Upload your documents (PDF, DOCX, TXT)
- Configure processing options
- Click "Build Index"
Using Scripts:
# Simple script approach
./simple_create_index.sh "My Documents" "path/to/document.pdf"
# Interactive script
python create_index_script.py
Using API:
# Create index
curl -X POST http://localhost:8000/indexes \
-H "Content-Type: application/json" \
-d '{"name": "My Index", "description": "My documents"}'
# Upload documents
curl -X POST http://localhost:8000/indexes/INDEX_ID/upload \
-F "[email protected]"
# Build index
curl -X POST http://localhost:8000/indexes/INDEX_ID/build
2. Start Chatting
Once your index is built:
- Create a Chat Session: Click "New Chat" or use an existing session
- Select Your Index: Choose which document collection to query
- Ask Questions: Type natural language questions about your documents
- Get Answers: Receive AI-generated responses with source citations
3. Advanced Features
Custom Model Configuration
# Use different models for different tasks
curl -X POST http://localhost:8000/sessions \
-H "Content-Type: application/json" \
-d '{
"title": "High Quality Session",
"model": "qwen3:8b",
"embedding_model": "Qwen/Qwen3-Embedding-4B"
}'
Batch Document Processing
# Process multiple documents at once
python demo_batch_indexing.py --config batch_indexing_config.json
API Integration
import requests
# Chat with your documents via API
response = requests.post('http://localhost:8000/chat', json={
'query': 'What are the key findings in the research papers?',
'session_id': 'your-session-id',
'search_type': 'hybrid',
'retrieval_k': 20
})
print(response.json()['response'])
🔧 Configuration
Model Configuration
LocalGPT supports multiple AI model providers with centralized configuration:
Ollama Models (Local Inference)
OLLAMA_CONFIG = {
"host": "http://localhost:11434",
"generation_model": "qwen3:8b", # Main text generation
"enrichment_model": "qwen3:0.6b" # Lightweight routing/enrichment
}
External Models (HuggingFace Direct)
EXTERNAL_MODELS = {
"embedding_model": "Qwen/Qwen3-Embedding-0.6B", # 1024 dimensions
"reranker_model": "answerdotai/answerai-colbert-small-v1", # ColBERT reranker
"fallback_reranker": "BAAI/bge-reranker-base" # Backup reranker
}
Pipeline Configuration
LocalGPT offers two main pipeline configurations:
Default Pipeline (Production-Ready)
"default": {
"description": "Production-ready pipeline with hybrid search, AI reranking, and verification",
"storage": {
"lancedb_uri": "./lancedb",
"text_table_name": "text_pages_v3",
"bm25_path": "./index_store/bm25"
},
"retrieval": {
"retriever": "multivector",
"search_type": "hybrid",
"late_chunking": {"enabled": True},
"dense": {"enabled": True, "weight": 0.7},
"bm25": {"enabled": True}
},
"reranker": {
"enabled": True,
"type": "ai",
"strategy": "rerankers-lib",
"model_name": "answerdotai/answerai-colbert-small-v1",
"top_k": 10
},
"query_decomposition": {"enabled": True, "max_sub_queries": 3},
"verification": {"enabled": True},
"retrieval_k": 20,
"contextual_enricher": {"enabled": True, "window_size": 1}
}
Fast Pipeline (Speed-Optimized)
"fast": {
"description": "Speed-optimized pipeline with minimal overhead",
"retrieval": {
"search_type": "vector_only",
"late_chunking": {"enabled": False}
},
"reranker": {"enabled": False},
"query_decomposition": {"enabled": False},
"verification": {"enabled": False},
"retrieval_k": 10,
"contextual_enricher": {"enabled": False}
}
Search Configuration
SEARCH_CONFIG = {
'hybrid': {
'dense_weight': 0.7,
'sparse_weight': 0.3,
'retrieval_k': 20,
'reranker_top_k': 10
}
}
🛠️ Troubleshooting
Common Issues
Installation Problems
# Check Python version
python --version # Should be 3.8+
# Check dependencies
pip list | grep -E "(torch|transformers|lancedb)"
# Reinstall dependencies
pip install -r requirements.txt --force-reinstall
Model Loading Issues
# Check Ollama status
ollama list
curl http://localhost:11434/api/tags
# Pull missing models
ollama pull qwen3:0.6b
Database Issues
# Check database connectivity
python -c "from backend.database import ChatDatabase; db = ChatDatabase(); print('✅ Database OK')"
# Reset database (WARNING: This deletes all data)
rm backend/chat_data.db
python -c "from backend.database import ChatDatabase; ChatDatabase().init_database()"
Performance Issues
# Check system resources
python system_health_check.py
# Monitor memory usage
htop # or Task Manager on Windows
# Optimize for low-memory systems
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512
Getting Help
-
Check Logs: The system creates structured logs in the
logs/directory:logs/system.log: Main system events and errorslogs/ollama.log: Ollama server logslogs/rag-api.log: RAG API processing logslogs/backend.log: Backend server logslogs/frontend.log: Frontend build and runtime logs
-
System Health: Run comprehensive diagnostics:
python system_health_check.py # Full system diagnostics python run_system.py --health # Service status check -
Health Endpoints: Check individual service health:
- Backend:
http://localhost:8000/health - RAG API:
http://localhost:8001/health - Ollama:
http://localhost:11434/api/tags
- Backend:
-
Documentation: Check the Technical Documentation
-
GitHub Issues: Report bugs and request features
-
Community: Join our Discord/Slack community
🔗 API Reference
Core Endpoints
Chat API
# Session-based chat (recommended)
POST /sessions/{session_id}/chat
Content-Type: application/json
{
"query": "What are the main topics discussed?",
"search_type": "hybrid",
"retrieval_k": 20,
"ai_rerank": true,
"context_window_size": 5
}
# Legacy chat endpoint
POST /chat
Content-Type: application/json
{
"query": "What are the main topics discussed?",
"session_id": "uuid",
"search_type": "hybrid",
"retrieval_k": 20
}
Index Management
# Create index
POST /indexes
Content-Type: application/json
{
"name": "My Index",
"description": "Description",
"config": "default"
}
# Get all indexes
GET /indexes
# Get specific index
GET /indexes/{id}
# Upload documents to index
POST /indexes/{id}/upload
Content-Type: multipart/form-data
files: [file1.pdf, file2.pdf, ...]
# Build index (process uploaded documents)
POST /indexes/{id}/build
Content-Type: application/json
{
"config_mode": "default",
"enable_enrich": true,
"chunk_size": 512
}
# Delete index
DELETE /indexes/{id}
Session Management
# Create session
POST /sessions
Content-Type: application/json
{
"title": "My Session",
"model": "qwen3:0.6b"
}
# Get all sessions
GET /sessions
# Get specific session
GET /sessions/{session_id}
# Get session documents
GET /sessions/{session_id}/documents
# Get session indexes
GET /sessions/{session_id}/indexes
# Link index to session
POST /sessions/{session_id}/indexes/{index_id}
# Delete session
DELETE /sessions/{session_id}
# Rename session
POST /sessions/{session_id}/rename
Content-Type: application/json
{
"new_title": "Updated Session Name"
}
Advanced Features
Query Decomposition
The system can break complex queries into sub-questions for better answers:
POST /sessions/{session_id}/chat
Content-Type: application/json
{
"query": "Compare the methodologies and analyze their effectiveness",
"query_decompose": true,
"compose_sub_answers": true
}
Answer Verification
Independent verification pass for accuracy using a separate verification model:
POST /sessions/{session_id}/chat
Content-Type: application/json
{
"query": "What are the key findings?",
"verify": true
}
Contextual Enrichment
Document context enrichment during indexing for better understanding:
# Enable during index building
POST /indexes/{id}/build
{
"enable_enrich": true,
"window_size": 2
}
Late Chunking
Better context preservation by chunking after embedding:
# Configure in pipeline
"late_chunking": {"enabled": true}
Streaming Chat
POST /chat/stream
Content-Type: application/json
{
"query": "Explain the methodology",
"session_id": "uuid",
"stream": true
}
Batch Processing
# Using the batch indexing script
python demo_batch_indexing.py --config batch_indexing_config.json
# Example batch configuration (batch_indexing_config.json):
{
"index_name": "Sample Batch Index",
"index_description": "Example batch index configuration",
"documents": [
"./rag_system/documents/invoice_1039.pdf",
"./rag_system/documents/invoice_1041.pdf"
],
"processing": {
"chunk_size": 512,
"chunk_overlap": 64,
"enable_enrich": true,
"enable_latechunk": true,
"enable_docling": true,
"embedding_model": "Qwen/Qwen3-Embedding-0.6B",
"generation_model": "qwen3:0.6b",
"retrieval_mode": "hybrid",
"window_size": 2
}
}
# API endpoint for batch processing
POST /batch/index
Content-Type: application/json
{
"file_paths": ["doc1.pdf", "doc2.pdf"],
"config": {
"chunk_size": 512,
"enable_enrich": true,
"enable_latechunk": true,
"enable_docling": true
}
}
For complete API documentation, see API_REFERENCE.md.
🏗️ Architecture
LocalGPT is built with a modular, scalable architecture:
graph TB
UI[Web Interface] --> API[Backend API]
API --> Agent[RAG Agent]
Agent --> Retrieval[Retrieval Pipeline]
Agent --> Generation[Generation Pipeline]
Retrieval --> Vector[Vector Search]
Retrieval --> BM25[BM25 Search]
Retrieval --> Rerank[Reranking]
Vector --> LanceDB[(LanceDB)]
BM25 --> BM25DB[(BM25 Index)]
Generation --> Ollama[Ollama Models]
Generation --> HF[Hugging Face Models]
API --> SQLite[(SQLite DB)]
Overview of the Retrieval Agent
graph TD
classDef llmcall fill:#e6f3ff,stroke:#007bff;
classDef pipeline fill:#e6ffe6,stroke:#28a745;
classDef cache fill:#fff3e0,stroke:#fd7e14;
classDef logic fill:#f8f9fa,stroke:#6c757d;
classDef thread stroke-dasharray: 5 5;
A(Start: Agent.run) --> B_asyncio.run(_run_async);
B --> C{_run_async};
C --> C1[Get Chat History];
C1 --> T1[Build Triage Prompt <br/> Query + Doc Overviews ];
T1 --> T2["(asyncio.to_thread)<br/>LLM Triage: RAG or LLM_DIRECT?"]; class T2 llmcall,thread;
T2 --> T3{Decision?};
T3 -- RAG --> RAG_Path;
T3 -- LLM_DIRECT --> LLM_Path;
subgraph RAG Path
RAG_Path --> R1[Format Query + History];
R1 --> R2["(asyncio.to_thread)<br/>Generate Query Embedding"]; class R2 pipeline,thread;
R2 --> R3{{Check Semantic Cache}}; class R3 cache;
R3 -- Hit --> R_Cache_Hit(Return Cached Result);
R_Cache_Hit --> R_Hist_Update;
R3 -- Miss --> R4{Decomposition <br/> Enabled?};
R4 -- Yes --> R5["(asyncio.to_thread)<br/>Decompose Raw Query"]; class R5 llmcall,thread;
R5 --> R6{{Run Sub-Queries <br/> Parallel RAG Pipeline}}; class R6 pipeline,thread;
R6 --> R7[Collect Results & Docs];
R7 --> R8["(asyncio.to_thread)<br/>Compose Final Answer"]; class R8 llmcall,thread;
R8 --> V1(RAG Answer);
R4 -- No --> R9["(asyncio.to_thread)<br/>Run Single Query <br/>(RAG Pipeline)"]; class R9 pipeline,thread;
R9 --> V1;
V1 --> V2{{Verification <br/> await verify_async}}; class V2 llmcall;
V2 --> V3(Final RAG Result);
V3 --> R_Cache_Store{{Store in Semantic Cache}}; class R_Cache_Store cache;
R_Cache_Store --> FinalResult;
end
subgraph Direct LLM Path
LLM_Path --> L1[Format Query + History];
L1 --> L2["(asyncio.to_thread)<br/>Generate Direct LLM Answer <br/> (No RAG)"]; class L2 llmcall,thread;
L2 --> FinalResult(Final Direct Result);
end
FinalResult --> R_Hist_Update(Update Chat History);
R_Hist_Update --> ZZZ(End: Return Result);
🤝 Contributing
We welcome contributions from developers of all skill levels! LocalGPT is an open-source project that benefits from community involvement.
🚀 Quick Start for Contributors
# Fork and clone the repository
git clone https://github.com/PromtEngineer/localGPT.git
cd localGPT
# Set up development environment
pip install -r requirements.txt
npm install
# Install Ollama and models
curl -fsSL https://ollama.ai/install.sh | sh
ollama pull qwen3:0.6b qwen3:8b
# Verify setup
python system_health_check.py
python run_system.py --mode dev
📋 How to Contribute
- 🐛 Report Bugs: Use our bug report template
- 💡 Request Features: Use our feature request template
- 🔧 Submit Code: Follow our development workflow
- 📚 Improve Docs: Help make our documentation better
📖 Detailed Guidelines
For comprehensive contributing guidelines, including:
- Development setup and workflow
- Coding standards and best practices
- Testing requirements
- Documentation standards
- Release process
👉 See our CONTRIBUTING.md guide
📄 License
This project is licensed under the MIT License - see the LICENSE file for details. For models, please check their respective licenses.
📞 Support
- Documentation: Technical Docs
- Issues: GitHub Issues
- Discussions: GitHub Discussions
- Business Deployment and Customization: Contact Us
Star History
Discover Repositories
Search across tracked repositories by name or description