Alishahryar1/free-claude-code
Use claude-code for free in the terminal, VSCode extension or discord like OpenClaw (voice supported)
Scale data-heavy AI workloads
while keeping costs low with S3-compatible storage.
Loading star history...
Health Score
75
Weekly Growth
+5.3K
+33.4% this week
Contributors
23
Total contributors
Open Issues
84
Use Cases & Benefits
About free-claude-code
🤖 Free Claude Code
Use Claude Code CLI & VSCode for free. No Anthropic API key required.
![]()
![]()
![]()
![]()
![]()
![]()
A lightweight proxy that routes Claude Code's Anthropic API calls to NVIDIA NIM (40 req/min free), OpenRouter (hundreds of models), LM Studio (fully local), or llama.cpp (local with Anthropic endpoints).
Quick Start · Providers · Discord Bot · Configuration · Development · Contributing
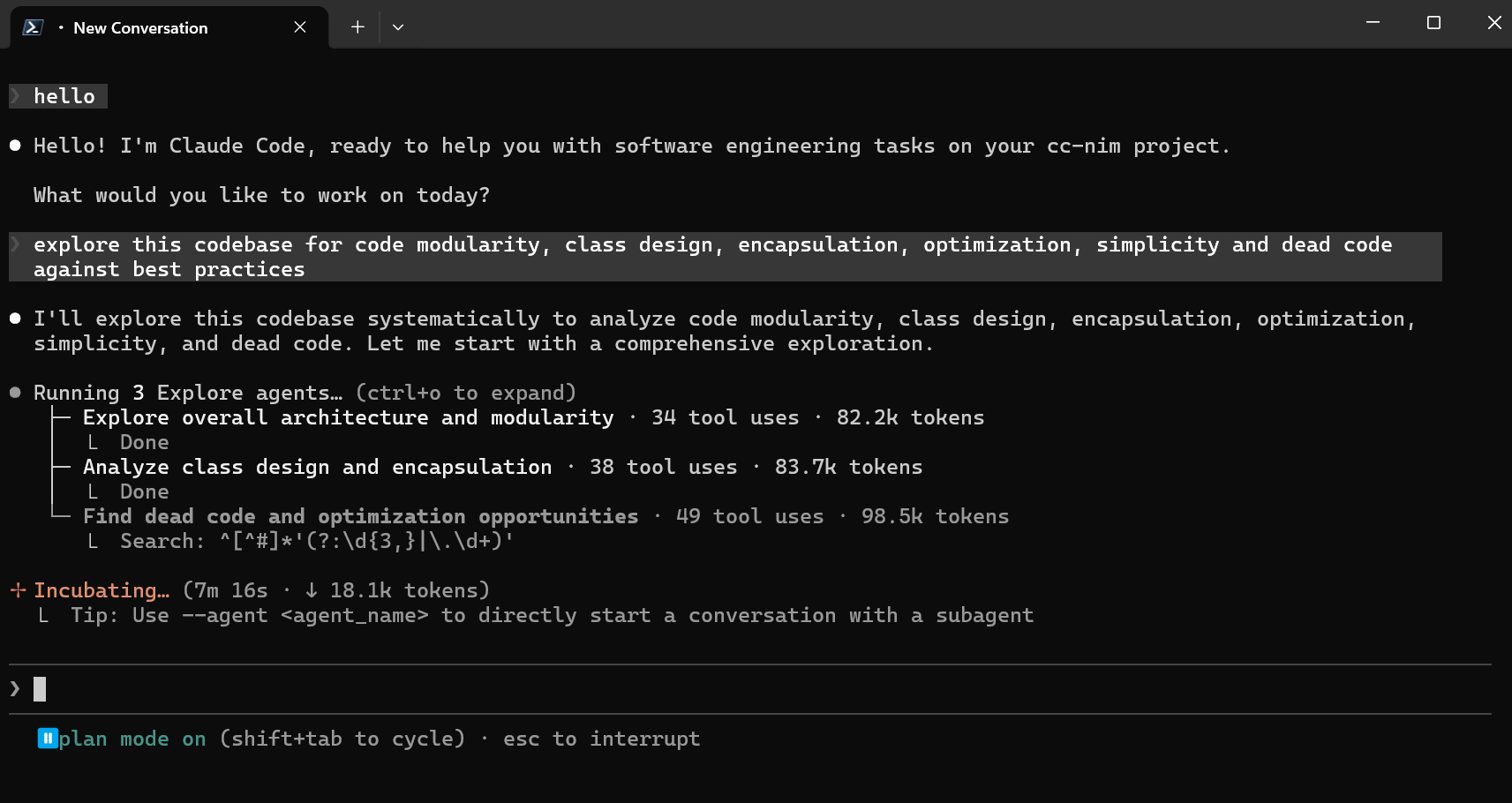
Claude Code running via NVIDIA NIM, completely free
Features
| Feature | Description |
|---|---|
| Zero Cost | 40 req/min free on NVIDIA NIM. Free models on OpenRouter. Fully local with LM Studio |
| Drop-in Replacement | Set 2 env vars. No modifications to Claude Code CLI or VSCode extension needed |
| 4 Providers | NVIDIA NIM, OpenRouter (hundreds of models), LM Studio (local), llama.cpp (llama-server) |
| Per-Model Mapping | Route Opus / Sonnet / Haiku to different models and providers. Mix providers freely |
| Thinking Token Support | Parses <think> tags and reasoning_content into native Claude thinking blocks |
| Heuristic Tool Parser | Models outputting tool calls as text are auto-parsed into structured tool use |
| Request Optimization | 5 categories of trivial API calls intercepted locally, saving quota and latency |
| Smart Rate Limiting | Proactive rolling-window throttle + reactive 429 exponential backoff + optional concurrency cap |
| Discord / Telegram Bot | Remote autonomous coding with tree-based threading, session persistence, and live progress |
| Subagent Control | Task tool interception forces run_in_background=False. No runaway subagents |
| Extensible | Clean BaseProvider and MessagingPlatform ABCs. Add new providers or platforms easily |
Quick Start
Prerequisites
- Get an API key (or use LM Studio / llama.cpp locally):
- NVIDIA NIM: build.nvidia.com/settings/api-keys
- OpenRouter: openrouter.ai/keys
- LM Studio: No API key needed. Run locally with LM Studio
- llama.cpp: No API key needed. Run
llama-serverlocally.
- Install Claude Code
Install uv
# Install uv (required to run the project)
pip install uv
If uv is already installed, run uv self update to get the latest version.
Clone & Configure
git clone https://github.com/Alishahryar1/free-claude-code.git
cd free-claude-code
cp .env.example .env
Choose your provider and edit .env:
NVIDIA NIM (40 req/min free, recommended)
NVIDIA_NIM_API_KEY="nvapi-your-key-here"
MODEL_OPUS="nvidia_nim/z-ai/glm4.7"
MODEL_SONNET="nvidia_nim/moonshotai/kimi-k2-thinking"
MODEL_HAIKU="nvidia_nim/stepfun-ai/step-3.5-flash"
MODEL="nvidia_nim/z-ai/glm4.7" # fallback
# Enable for thinking models (kimi, nemotron). Leave false for others (e.g. Mistral).
NIM_ENABLE_THINKING=true
OpenRouter (hundreds of models)
OPENROUTER_API_KEY="sk-or-your-key-here"
MODEL_OPUS="open_router/deepseek/deepseek-r1-0528:free"
MODEL_SONNET="open_router/openai/gpt-oss-120b:free"
MODEL_HAIKU="open_router/stepfun/step-3.5-flash:free"
MODEL="open_router/stepfun/step-3.5-flash:free" # fallback
LM Studio (fully local, no API key)
MODEL_OPUS="lmstudio/unsloth/MiniMax-M2.5-GGUF"
MODEL_SONNET="lmstudio/unsloth/Qwen3.5-35B-A3B-GGUF"
MODEL_HAIKU="lmstudio/unsloth/GLM-4.7-Flash-GGUF"
MODEL="lmstudio/unsloth/GLM-4.7-Flash-GGUF" # fallback
llama.cpp (fully local, no API key)
LLAMACPP_BASE_URL="http://localhost:8080/v1"
MODEL_OPUS="llamacpp/local-model"
MODEL_SONNET="llamacpp/local-model"
MODEL_HAIKU="llamacpp/local-model"
MODEL="llamacpp/local-model"
Mix providers
Each MODEL_* variable can use a different provider. MODEL is the fallback for unrecognized Claude models.
NVIDIA_NIM_API_KEY="nvapi-your-key-here"
OPENROUTER_API_KEY="sk-or-your-key-here"
MODEL_OPUS="nvidia_nim/moonshotai/kimi-k2.5"
MODEL_SONNET="open_router/deepseek/deepseek-r1-0528:free"
MODEL_HAIKU="lmstudio/unsloth/GLM-4.7-Flash-GGUF"
MODEL="nvidia_nim/z-ai/glm4.7" # fallback
Optional Authentication (restrict access to your proxy)
Set ANTHROPIC_AUTH_TOKEN in .env to require clients to authenticate:
ANTHROPIC_AUTH_TOKEN="your-secret-token-here"
How it works:
- If
ANTHROPIC_AUTH_TOKENis empty (default), no authentication is required (backward compatible) - If set, clients must provide the same token via the
ANTHROPIC_AUTH_TOKENheader - The
claude-pickscript automatically reads the token from.envif configured
Example usage:
# With authentication
ANTHROPIC_AUTH_TOKEN="your-secret-token-here" \
ANTHROPIC_BASE_URL="http://localhost:8082" claude
# claude-pick automatically uses the configured token
claude-pick
Use this feature if:
- Running the proxy on a public network
- Sharing the server with others but restricting access
- Wanting an additional layer of security
Run It
Terminal 1: Start the proxy server:
uv run uvicorn server:app --host 0.0.0.0 --port 8082
Terminal 2: Run Claude Code:
Powershell
$env:ANTHROPIC_AUTH_TOKEN="freecc"; $env:ANTHROPIC_BASE_URL="http://localhost:8082"; claude
Bash
ANTHROPIC_AUTH_TOKEN="freecc" ANTHROPIC_BASE_URL="http://localhost:8082" claude
That's it! Claude Code now uses your configured provider for free.
VSCode Extension Setup
- Start the proxy server (same as above).
- Open Settings (
Ctrl + ,) and search forclaude-code.environmentVariables. - Click Edit in settings.json and add:
"claudeCode.environmentVariables": [
{ "name": "ANTHROPIC_BASE_URL", "value": "http://localhost:8082" },
{ "name": "ANTHROPIC_AUTH_TOKEN", "value": "freecc" }
]
- Reload extensions.
- If you see the login screen: Click Anthropic Console, then authorize. The extension will start working. You may be redirected to buy credits in the browser; ignore it — the extension already works.
To switch back to Anthropic models, comment out the added block and reload extensions.
Multi-Model Support (Model Picker)
claude-pick is an interactive model selector that lets you choose any model from your active provider each time you launch Claude, without editing MODEL in .env.
https://github.com/user-attachments/assets/9a33c316-90f8-4418-9650-97e7d33ad645
1. Install fzf:
brew install fzf # macOS/Linux
2. Add the alias to ~/.zshrc or ~/.bashrc:
alias claude-pick="/absolute/path/to/free-claude-code/claude-pick"
Then reload your shell (source ~/.zshrc or source ~/.bashrc) and run claude-pick.
Or use a fixed model alias (no picker needed):
alias claude-kimi='ANTHROPIC_BASE_URL="http://localhost:8082" ANTHROPIC_AUTH_TOKEN="freecc:moonshotai/kimi-k2.5" claude'
Install as a Package (no clone needed)
uv tool install git+https://github.com/Alishahryar1/free-claude-code.git
fcc-init # creates ~/.config/free-claude-code/.env from the built-in template
Edit ~/.config/free-claude-code/.env with your API keys and model names, then:
free-claude-code # starts the server
To update:
uv tool upgrade free-claude-code
How It Works
┌──�───────────────┐ ┌──────────────────────┐ ┌──────────────────┐
│ Claude Code │───────>│ Free Claude Code │───────>│ LLM Provider │
│ CLI / VSCode │<───────│ Proxy (:8082) │<───────│ NIM / OR / LMS │
└─────────────────┘ └──────────────────────┘ └──────────────────┘
Anthropic API OpenAI-compatible
format (SSE) format (SSE)
- Transparent proxy: Claude Code sends standard Anthropic API requests; the proxy forwards them to your configured provider
- Per-model routing: Opus / Sonnet / Haiku requests resolve to their model-specific backend, with
MODELas fallback - Request optimization: 5 categories of trivial requests (quota probes, title generation, prefix detection, suggestions, filepath extraction) are intercepted and responded to locally without using API quota
- Format translation: Requests are translated from Anthropic format to the provider's OpenAI-compatible format and streamed back
- Thinking tokens:
<think>tags andreasoning_contentfields are converted into native Claude thinking blocks
Providers
| Provider | Cost | Rate Limit | Best For |
|---|---|---|---|
| NVIDIA NIM | Free | 40 req/min | Daily driver, generous free tier |
| OpenRouter | Free / Paid | Varies | Model variety, fallback options |
| LM Studio | Free (local) | Unlimited | Privacy, offline use, no rate limits |
| llama.cpp | Free (local) | Unlimited | Lightweight local inference engine |
Models use a prefix format: provider_prefix/model/name. An invalid prefix causes an error.
| Provider | MODEL prefix | API Key Variable | Default Base URL |
|---|---|---|---|
| NVIDIA NIM | nvidia_nim/... | NVIDIA_NIM_API_KEY | integrate.api.nvidia.com/v1 |
| OpenRouter | open_router/... | OPENROUTER_API_KEY | openrouter.ai/api/v1 |
| LM Studio | lmstudio/... | (none) | localhost:1234/v1 |
| llama.cpp | llamacpp/... | (none) | localhost:8080/v1 |
NVIDIA NIM models
Popular models (full list in nvidia_nim_models.json):
nvidia_nim/minimaxai/minimax-m2.5nvidia_nim/qwen/qwen3.5-397b-a17bnvidia_nim/z-ai/glm5nvidia_nim/moonshotai/kimi-k2.5nvidia_nim/stepfun-ai/step-3.5-flash
Browse: build.nvidia.com · Update list: curl "https://integrate.api.nvidia.com/v1/models" > nvidia_nim_models.json
OpenRouter models
Popular free models:
open_router/arcee-ai/trinity-large-preview:freeopen_router/stepfun/step-3.5-flash:freeopen_router/deepseek/deepseek-r1-0528:freeopen_router/openai/gpt-oss-120b:free
Browse: openrouter.ai/models · Free models
LM Studio models
Run models locally with LM Studio. Load a model in the Chat or Developer tab, then set MODEL to its identifier.
Examples with native tool-use support:
LiquidAI/LFM2-24B-A2B-GGUFunsloth/MiniMax-M2.5-GGUFunsloth/GLM-4.7-Flash-GGUFunsloth/Qwen3.5-35B-A3B-GGUF
Browse: model.lmstudio.ai
llama.cpp models
Run models locally using llama-server. Ensure you have a tool-capable GGUF. Set MODEL to whatever arbitrary name you'd like (e.g. llamacpp/my-model), as llama-server ignores the model name when run via /v1/messages.
See the Unsloth docs for detailed instructions and capable models: https://unsloth.ai/docs/models/qwen3.5#qwen3.5-small-0.8b-2b-4b-9b
Discord Bot
Control Claude Code remotely from Discord (or Telegram). Send tasks, watch live progress, and manage multiple concurrent sessions.
Capabilities:
- Tree-based message threading: reply to a message to fork the conversation
- Session persistence across server restarts
- Live streaming of thinking tokens, tool calls, and results
- Unlimited concurrent Claude CLI sessions (concurrency controlled by
PROVIDER_MAX_CONCURRENCY) - Voice notes: send voice messages; they are transcribed and processed as regular prompts
- Commands:
/stop(cancel a task; reply to a message to stop only that task),/clear(reset all sessions, or reply to clear a branch),/stats
Setup
-
Create a Discord Bot: Go to Discord Developer Portal, create an application, add a bot, and copy the token. Enable Message Content Intent under Bot settings.
-
Edit
.env:
MESSAGING_PLATFORM="discord"
DISCORD_BOT_TOKEN="your_discord_bot_token"
ALLOWED_DISCORD_CHANNELS="123456789,987654321"
Enable Developer Mode in Discord (Settings → Advanced), then right-click a channel and "Copy ID". Comma-separate multiple channels. If empty, no channels are allowed.
- Configure the workspace (where Claude will operate):
CLAUDE_WORKSPACE="./agent_workspace"
ALLOWED_DIR="C:/Users/yourname/projects"
- Start the server:
uv run uvicorn server:app --host 0.0.0.0 --port 8082
- Invite the bot via OAuth2 URL Generator (scopes:
bot, permissions: Read Messages, Send Messages, Manage Messages, Read Message History).
Telegram
Set MESSAGING_PLATFORM=telegram and configure:
TELEGRAM_BOT_TOKEN="123456789:ABCdefGHIjklMNOpqrSTUvwxYZ"
ALLOWED_TELEGRAM_USER_ID="your_telegram_user_id"
Get a token from @BotFather; find your user ID via @userinfobot.
Voice Notes
Send voice messages on Discord or Telegram; they are transcribed and processed as regular prompts.
| Backend | Description | API Key |
|---|---|---|
| Local Whisper (default) | Hugging Face Whisper — free, offline, CUDA compatible | not required |
| NVIDIA NIM | Whisper/Parakeet models via gRPC | NVIDIA_NIM_API_KEY |
Install the voice extras:
# If you cloned the repo:
uv sync --extra voice_local # Local Whisper
uv sync --extra voice # NVIDIA NIM
uv sync --extra voice --extra voice_local # Both
# If you installed as a package (no clone):
uv tool install "free-claude-code[voice_local] @ git+https://github.com/Alishahryar1/free-claude-code.git"
uv tool install "free-claude-code[voice] @ git+https://github.com/Alishahryar1/free-claude-code.git"
uv tool install "free-claude-code[voice,voice_local] @ git+https://github.com/Alishahryar1/free-claude-code.git"
Configure via WHISPER_DEVICE (cpu | cuda | nvidia_nim) and WHISPER_MODEL. See the Configuration table for all voice variables and supported model values.
Configuration
Core
| Variable | Description | Default |
|---|---|---|
MODEL | Fallback model (provider/model/name format; invalid prefix → error) | nvidia_nim/stepfun-ai/step-3.5-flash |
MODEL_OPUS | Model for Claude Opus requests (falls back to MODEL) | nvidia_nim/z-ai/glm4.7 |
MODEL_SONNET | Model for Claude Sonnet requests (falls back to MODEL) | open_router/arcee-ai/trinity-large-preview:free |
MODEL_HAIKU | Model for Claude Haiku requests (falls back to MODEL) | open_router/stepfun/step-3.5-flash:free |
NVIDIA_NIM_API_KEY | NVIDIA API key | required for NIM |
NIM_ENABLE_THINKING | Send chat_template_kwargs + reasoning_budget on NIM requests. Enable for thinking models (kimi, nemotron); leave false for others (e.g. Mistral) | false |
OPENROUTER_API_KEY | OpenRouter API key | required for OpenRouter |
LM_STUDIO_BASE_URL | LM Studio server URL | http://localhost:1234/v1 |
LLAMACPP_BASE_URL | llama.cpp server URL | http://localhost:8080/v1 |
Rate Limiting & Timeouts
| Variable | Description | Default |
|---|---|---|
PROVIDER_RATE_LIMIT | LLM API requests per window | 40 |
PROVIDER_RATE_WINDOW | Rate limit window (seconds) | 60 |
PROVIDER_MAX_CONCURRENCY | Max simultaneous open provider streams | 5 |
HTTP_READ_TIMEOUT | Read timeout for provider requests (s) | 120 |
HTTP_WRITE_TIMEOUT | Write timeout for provider requests (s) | 10 |
HTTP_CONNECT_TIMEOUT | Connect timeout for provider requests (s) | 2 |
Messaging & Voice
| Variable | Description | Default |
|---|---|---|
MESSAGING_PLATFORM | discord or telegram | discord |
DISCORD_BOT_TOKEN | Discord bot token | "" |
ALLOWED_DISCORD_CHANNELS | Comma-separated channel IDs (empty = none allowed) | "" |
TELEGRAM_BOT_TOKEN | Telegram bot token | "" |
ALLOWED_TELEGRAM_USER_ID | Allowed Telegram user ID | "" |
CLAUDE_WORKSPACE | Directory where the agent operates | ./agent_workspace |
ALLOWED_DIR | Allowed directories for the agent | "" |
MESSAGING_RATE_LIMIT | Messaging messages per window | 1 |
MESSAGING_RATE_WINDOW | Messaging window (seconds) | 1 |
VOICE_NOTE_ENABLED | Enable voice note handling | true |
WHISPER_DEVICE | cpu | cuda | nvidia_nim | cpu |
WHISPER_MODEL | Whisper model (local: tiny/base/small/medium/large-v2/large-v3/large-v3-turbo; NIM: openai/whisper-large-v3, nvidia/parakeet-ctc-1.1b-asr, etc.) | base |
HF_TOKEN | Hugging Face token for faster downloads (local Whisper, optional) | — |
Advanced: Request optimization flags
These are enabled by default and intercept trivial Claude Code requests locally to save API quota.
| Variable | Description | Default |
|---|---|---|
FAST_PREFIX_DETECTION | Enable fast prefix detection | true |
ENABLE_NETWORK_PROBE_MOCK | Mock network probe requests | true |
ENABLE_TITLE_GENERATION_SKIP | Skip title generation requests | true |
ENABLE_SUGGESTION_MODE_SKIP | Skip suggestion mode requests | true |
ENABLE_FILEPATH_EXTRACTION_MOCK | Mock filepath extraction | true |
See .env.example for all supported parameters.
Development
Project Structure
free-claude-code/
├── server.py # Entry point
├── api/ # FastAPI routes, request detection, optimization handlers
├── providers/ # BaseProvider, OpenAICompatibleProvider, NIM, OpenRouter, LM Studio, llamacpp
│ └── common/ # Shared utils (SSE builder, message converter, parsers, error mapping)
├── messaging/ # MessagingPlatform ABC + Discord/Telegram bots, session management
├── config/ # Settings, NIM config, logging
├── cli/ # CLI session and process management
└── tests/ # Pytest test suite
Commands
uv run ruff format # Format code
uv run ruff check # Lint
uv run ty check # Type checking
uv run pytest # Run tests
Extending
Adding an OpenAI-compatible provider (Groq, Together AI, etc.) — extend OpenAICompatibleProvider:
from providers.openai_compat import OpenAICompatibleProvider
from providers.base import ProviderConfig
class MyProvider(OpenAICompatibleProvider):
def __init__(self, config: ProviderConfig):
super().__init__(config, provider_name="MYPROVIDER",
base_url="https://api.example.com/v1", api_key=config.api_key)
Adding a fully custom provider — extend BaseProvider directly and implement stream_response().
Adding a messaging platform — extend MessagingPlatform in messaging/ and implement start(), stop(), send_message(), edit_message(), and on_message().
Contributing
- Report bugs or suggest features via Issues
- Add new LLM providers (Groq, Together AI, etc.)
- Add new messaging platforms (Slack, etc.)
- Improve test coverage
- Not accepting Docker integration PRs for now
git checkout -b my-feature
uv run ruff format && uv run ruff check && uv run ty check && uv run pytest
# Open a pull request
License
MIT License. See LICENSE for details.
Built with FastAPI, OpenAI Python SDK, discord.py, and python-telegram-bot.
Discover Repositories
Search across tracked repositories by name or description